Linked Open Data
Formación EJIE Marzo 2016



| 9:00 - 10:00 | Introducción a Linked Open Data |
| 10:00 - 10:30 | Descanso |
| 10:30 - 13:30 | RDF |
Día 1
| 9:00 - 10:30 | SPARQL |
| 10:30 - 11:30 | OWL |
| 11:30 - 12:00 | Descanso |
| 12:00 - 13:00 | Implementación Linked Data |
Día 2
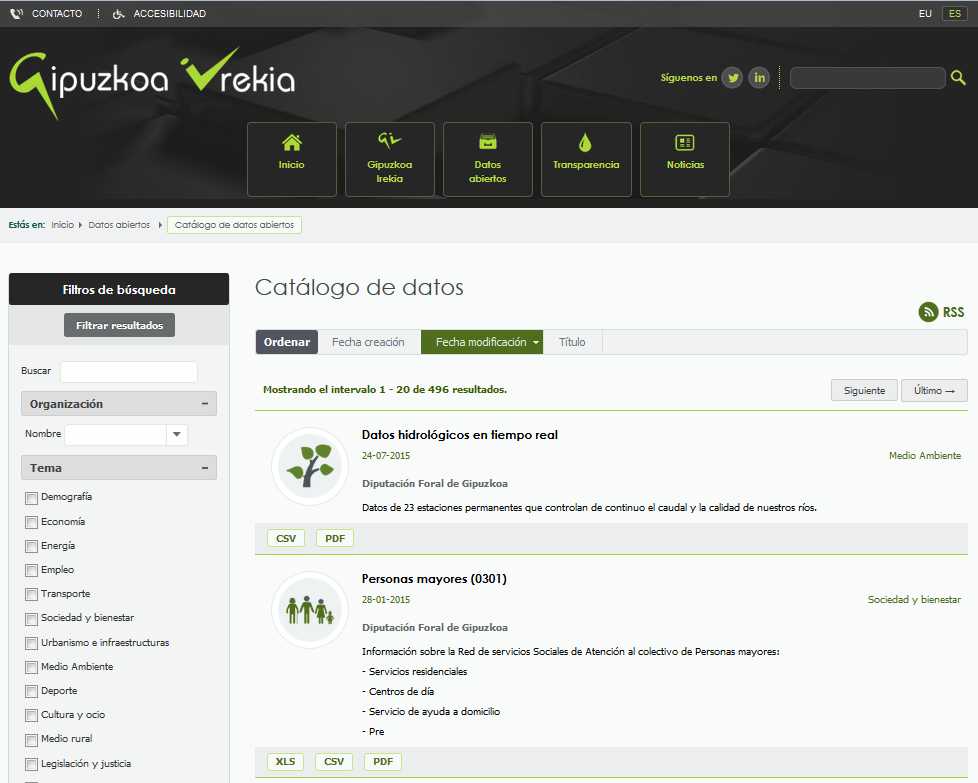
Introducción a Linked Open Data
Open Data
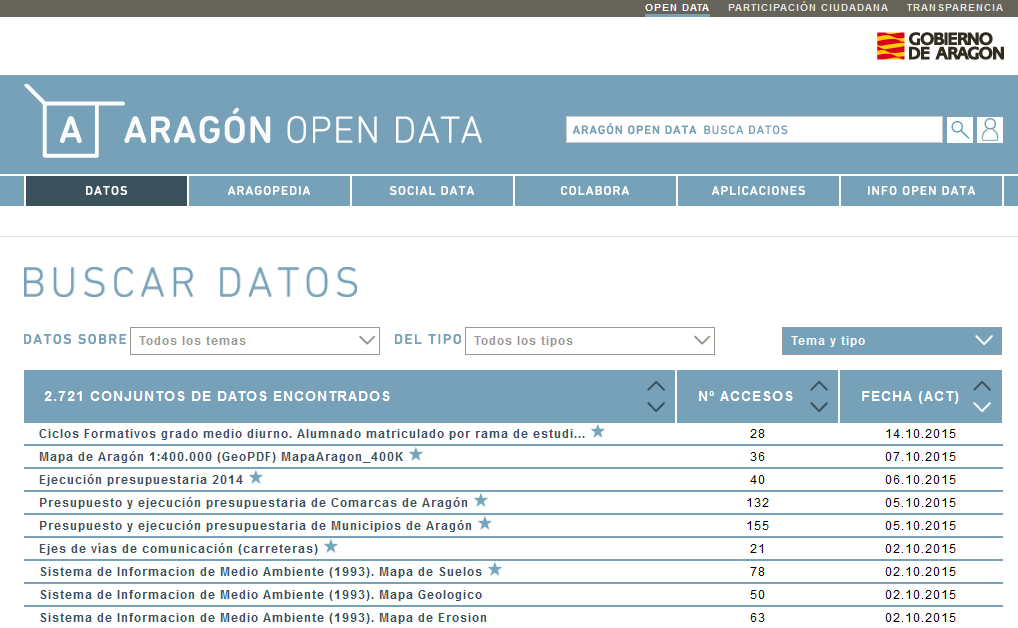
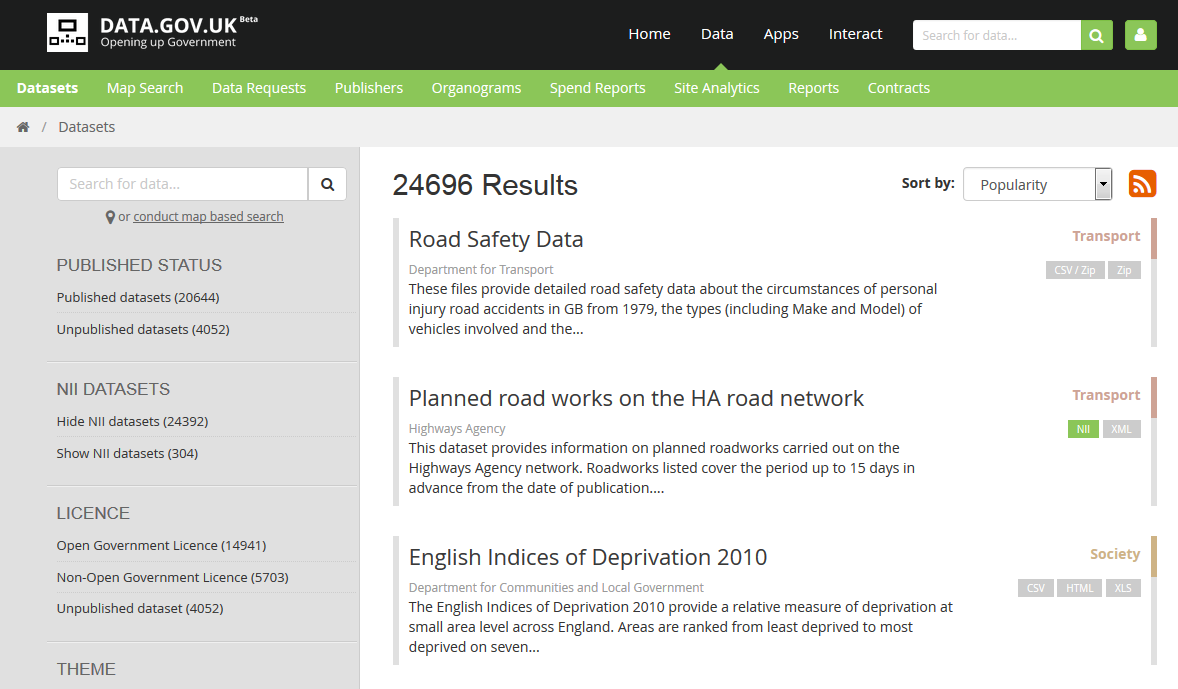
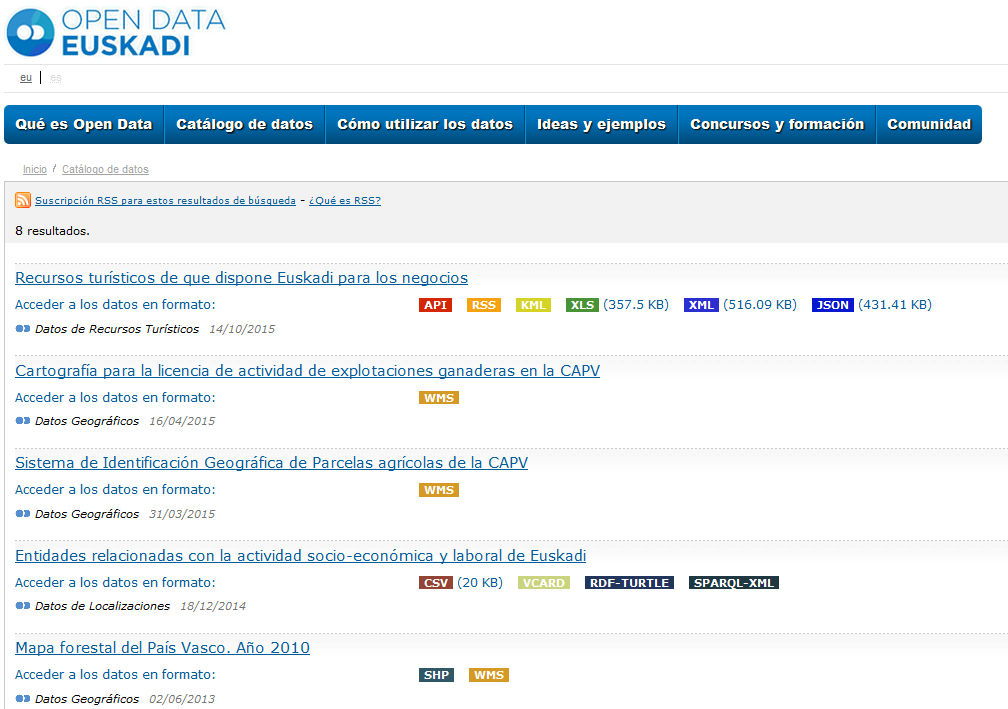
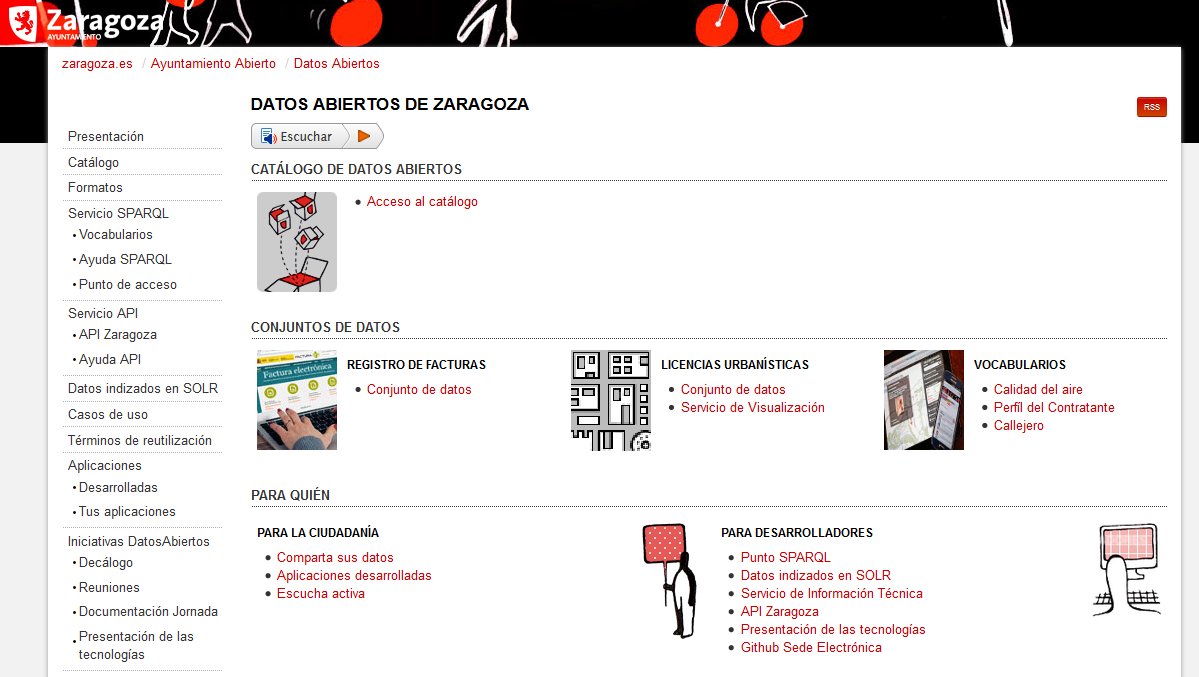
- Soluciones "out of the box" (ej. CKAN)
- Soluciones a medida
- APIs REST / Servicios Web / ...
- Descarga de archivos
Linked Data
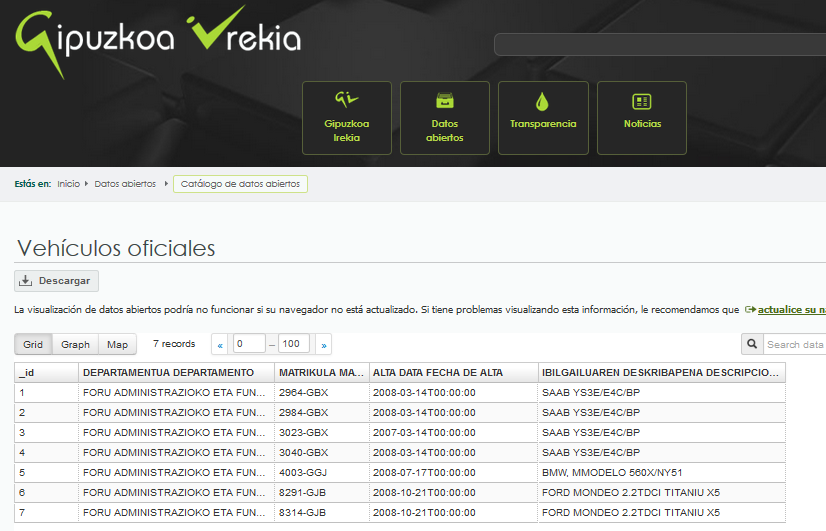
Datos abiertos para una participación ciudadana efectiva mediante Reutilización de Información del Sector Público (RISP)
Datos localizables, accesibles e interoperables, tanto para humanos como para maquinas

LEY DE TRANSPARENCIA, PARTICIPACIÓN CIUDADANA Y BUEN GOBIERNO DEL SECTOR PÚBLICO VASCO
De modo general los datos deben suministrarse sin someterse a licencia o condición específica alguna para facilitar su redistribución, reutilización y aprovechamiento en un formato digital, estandarizado y abierto, de modo libre y gratuito, siguiendo una estructura clara y explícita que permita su comprensión y reutilización, tanto por la ciudadanía como por agentes computacionales
Linked Data
CMS
BBDDs
XML
CSV
...
Archivos
APIs
WEB
Archivos
APIs
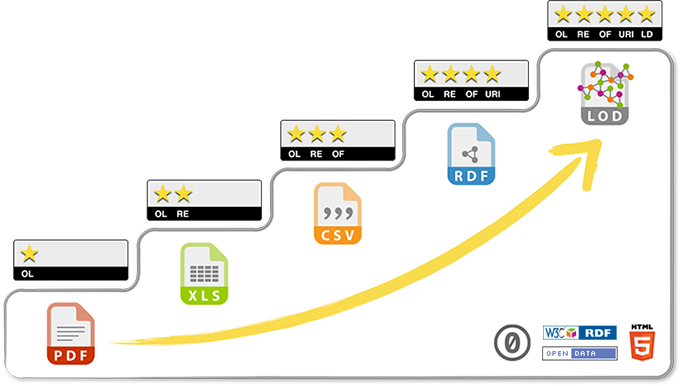
publica tus datos en la Web (con cualquier formato) y bajo una licencia abierta
publícalos como datos estructurados
usa formatos no propietarios
usa URIs para denotar cosas, así la gente puede apuntar a estas
enlaza tus datos a otros datos para proveer contexto
Linked Data nos permite publicar datos interoperables ...
... y muchas otras ventajas
Principios Linked Data
1.- Usar URIs (Uniform Resource Identifier) para identificar entidades
2.- Usar URIs que son accesibles mediante el protocolo HTTP, para que usuarios o agentes automáticos puedan acceder a las entidades
3.- Cuando se acceda a la entidad, proveer datos sobre la entidad en formatos estándar y abiertos, como RDF (Resource Description Framework)
4.- Añadir en los datos que publicamos en RDF enlaces a las URIs de otras entidades, de modo que un usuario o agente pueda navegar por la red de datos y descubrir más datos que también siguen los principios Linked Data
Linked Data
Utilizar maquinaria Web (URIs HTTP), para identificar y localizar entidades: http://example.com/entity
Utilizar un modelo de datos común, tripleta RDF, para integrar datos en los que aparecen esa entidades

«base de datos universal»
Ventajas Linked Data
Descubrimiento e integración de datos
Programación de agentes que consuman los datos
Actualización de datos mediante enlaces
Consultas complejas
Ventajas Linked Data
Con Linked Data cualquiera puede publicar datos y enlazarlos a otros datos
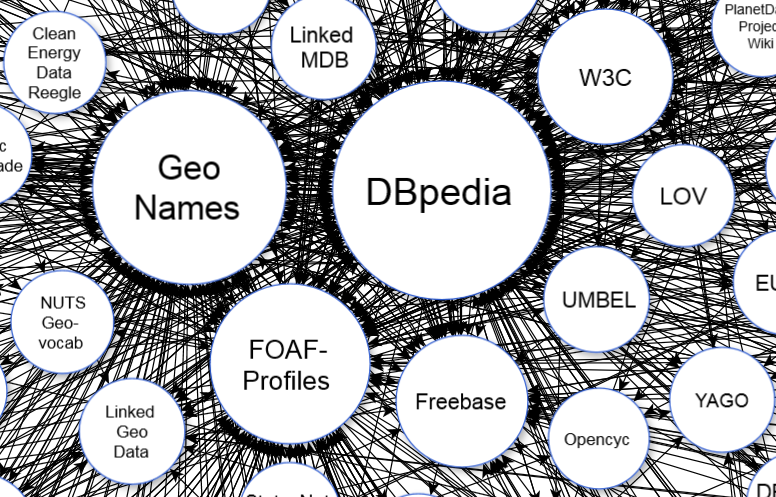
El conjunto de datos abiertos publicados mediante Linked Data forma la «nube Linked Open Data»
Cada vez más instituciones públicas de todo el mundo usan Linked Data para publicar sus datos



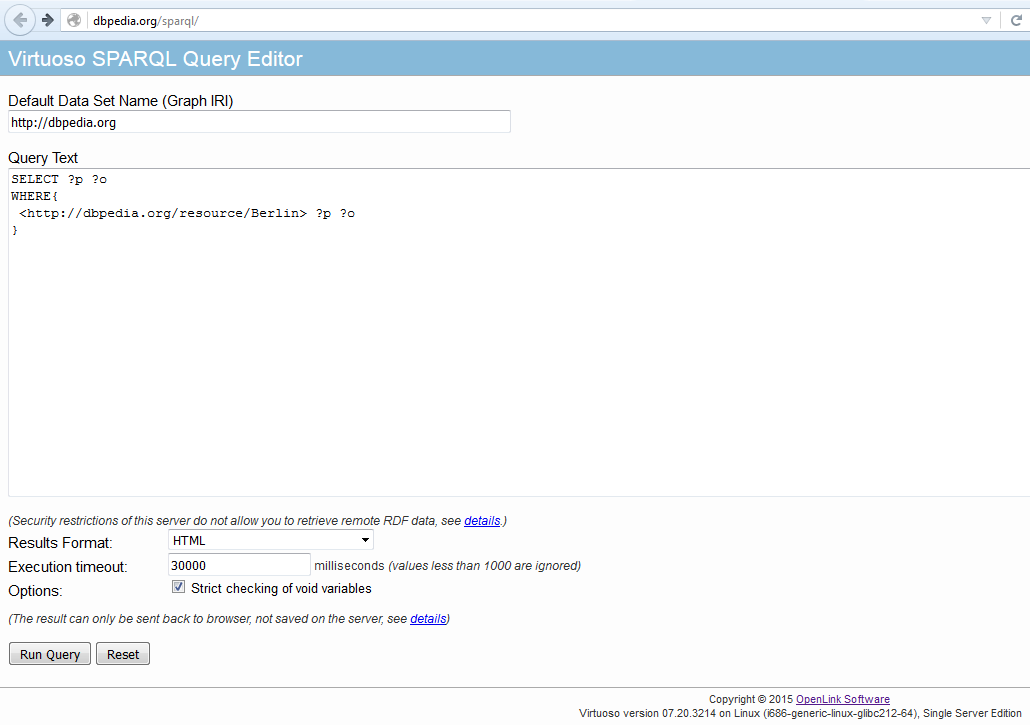
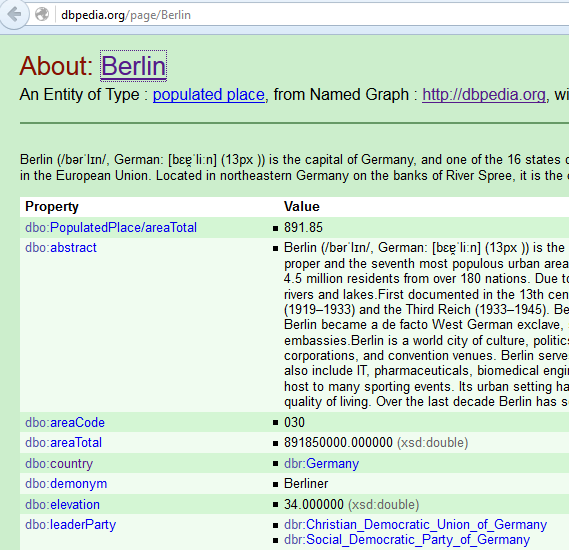
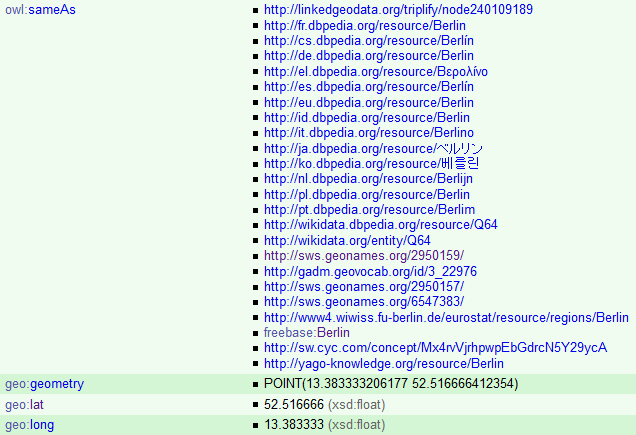
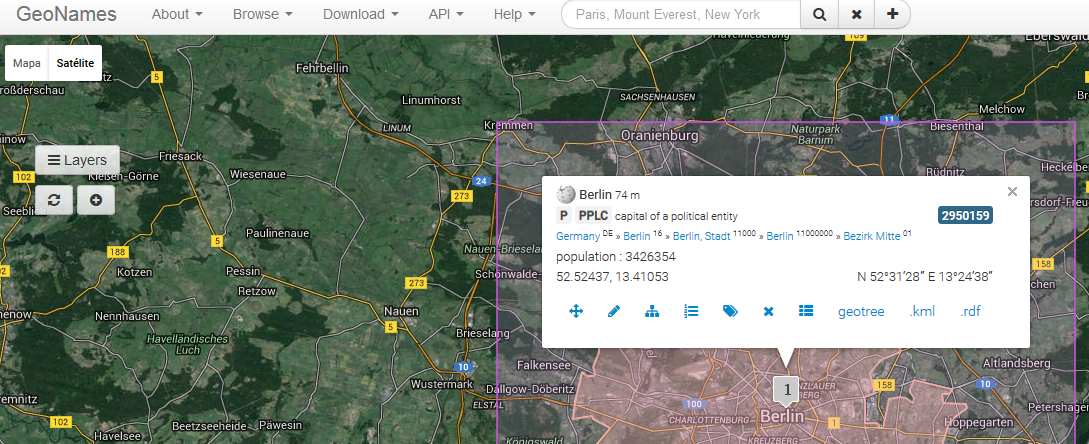
http://dbpedia.org/resource/Berlin
http://www.geonames.org/2950159
owl:sameAs
HTML
RDF
HTML
RDF
URIs = identificadores
Negociacion contenido (conneg)
curl -L -H "Accept: text/html" "http://dbpedia.org/resource/Berlin"

curl -L -H "Accept: application/rdf+xml" "http://dbpedia.org/resource/Berlin"

curl -L -H "Accept: text/html" "http://sws.geonames.org/2950159/"
curl -L -H "Accept: application/rdf+xml" "http://sws.geonames.org/2950159/"

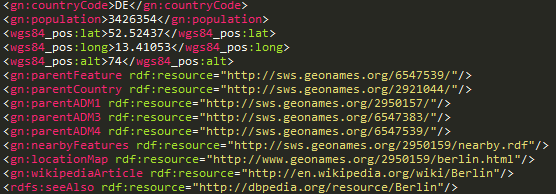
Pioneros
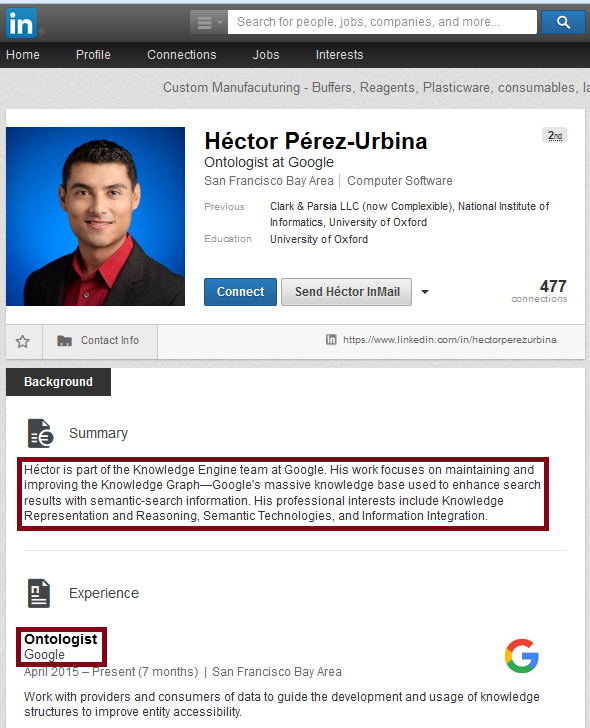
Google Knowledge Graph


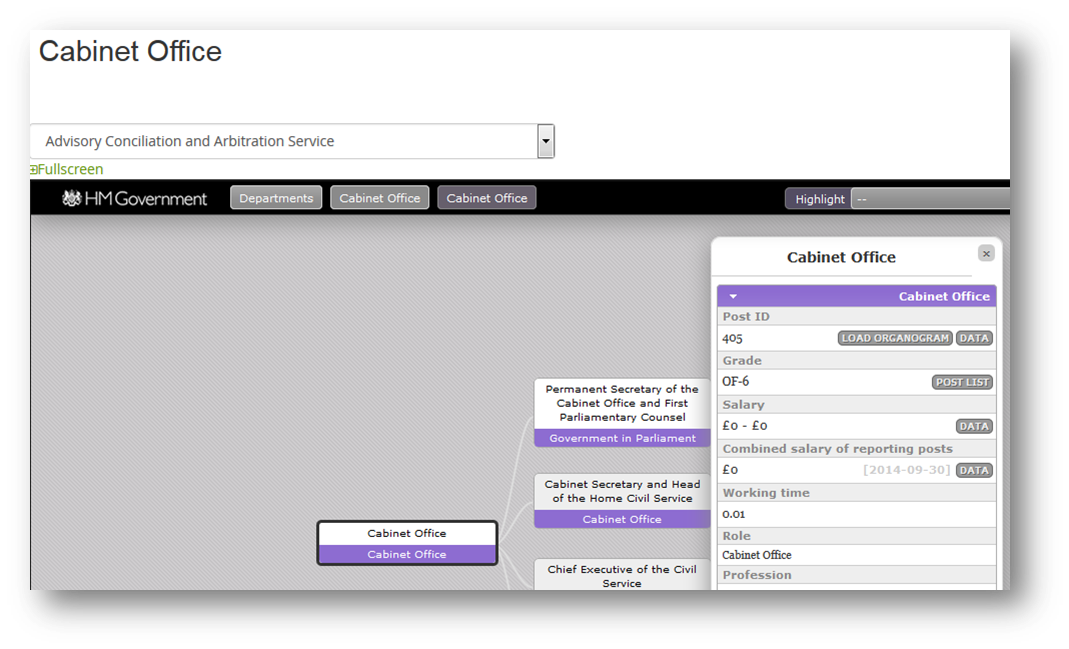
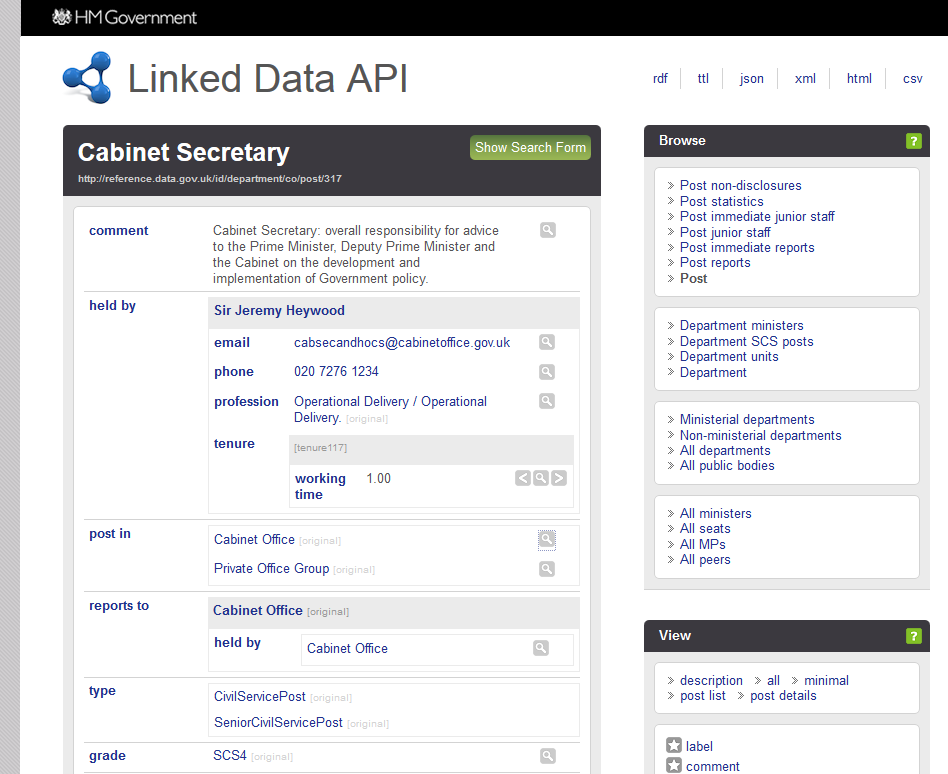
Linked Open Data UK
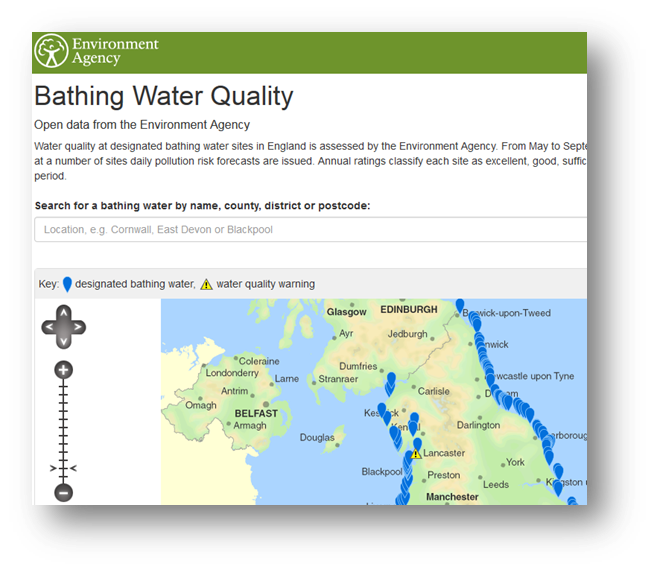
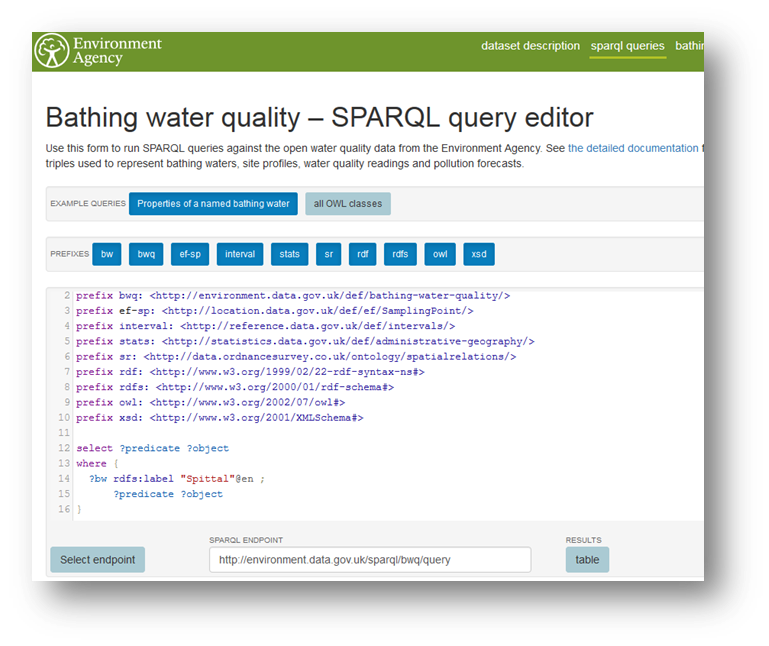
Linked Open Data UK
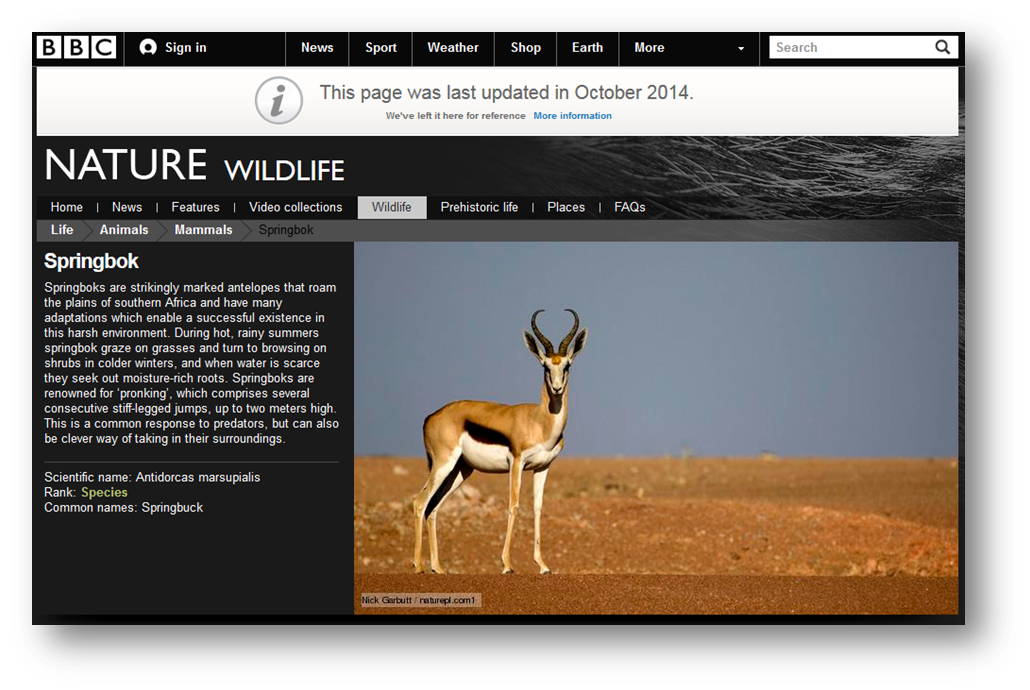
BBC UK
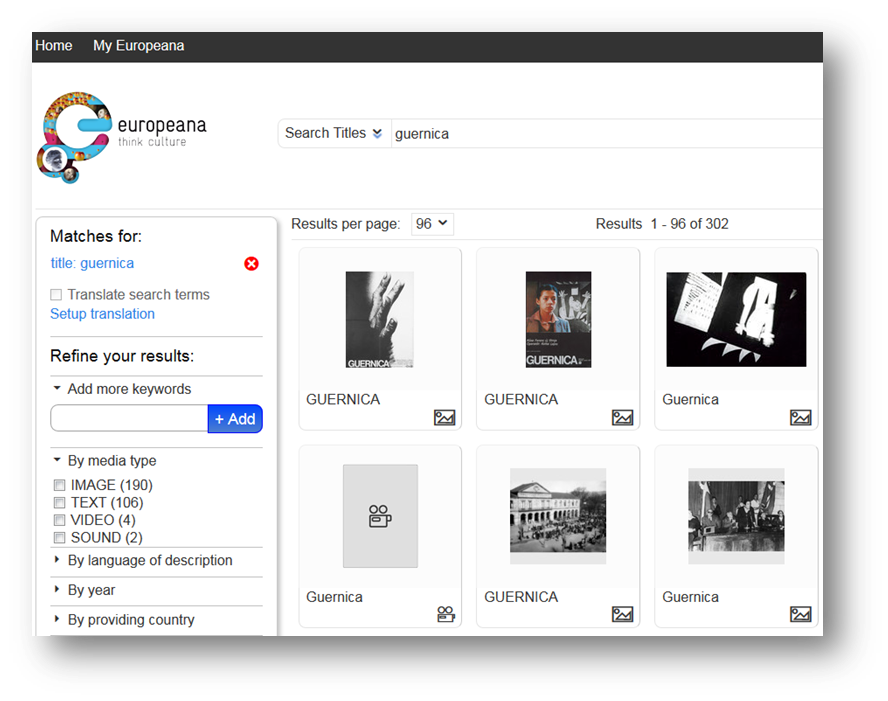
Europeana EU
Publicar Linked Open Data
Linked Data
Un método para publicar datos directamente en la Web
Propuesto por el W3C
http://www.w3.org/standards/semanticweb/data
Pila tecnologías Web Semántica W3C
OWL: "esquema" para RDF
SPARQL: consultas contra RDF
RDF: representar relaciones
entre entidades ("HTML para datos")
URI: identificar entidades

Linked Data
Publicar datos:
- Con "semántica" explícita
- Con enlaces
Semántica
RDF ofrece el triple, un modelo de datos explícito y homogéneo: una "frase" estándar que los ordenadores pueden "entender"

Enlaces
En el triple, cada entidad (sujeto, predicado, objeto) tiene una URI que lo identifica
Los datos son enlazados a otros datos a través de la Web, con enlaces explícitos

Grafo

Red global de datos enlazados
SPARQL
SELECT ?lugar ?nombre
WHERE {
?lugar <http://dbpedia.org/located_in> <http://gip.eus/donostia> .
?lugar rdfs:label ?nombre
}
SPARQL endpoint (Triple Store)
Consultas federadas
Integración
(SERVICE)
- URIs = "keys"
- Enlaces
OWL
Crear ontologías mediante Web Ontology Language
Ontología: "esquema" que describe el conocimiento sobre los datos
Tiene clases de individuos y define las condiciones para pertenecer a una clase
Es un lenguaje axiomatico con semantica precisa >> razonamiento automático
Algunas Triple Stores incluyen razonamiento automático en consultas
sujeto/objeto RDF >> rdf:type >> URI Clase OWL
OWL

1.- Convertir datos a RDF
Proceso publicación
Linked Data
2.- Persistir datos RDF y enlazarlos a la nube Linked Open Data
3.- Crear front-end web para consumo de datos
Arquitectura Linked Data
Triple Store: almacena RDF
SPARQL endpoint: interfaz de consulta a Triple Store (humanos y máquinas)
Servidor Linked Data: sirve HTML o datos RDF mediante negociación de contenido
Triple store: Almacenar RDF, SPARQL endpoint
Servidor Linked Data: acceso web, negociación contenido








Arquitectura Linked Data

Interfaz datos
Interfaz para programadores/expertos en datos
Análisis complejos de los datos/nueva aplicaciones
SPARQL: Consultas complejas contra los datos, incluso combinando diferentes «bolas» de la nube Linked Open Data (datasets externos)
RDF: Crear programas autónomos que «naveguen» por los datos, recolectando datos (agentes)
Interfaz datos SPARQL
curl "http://dbpedia.org/sparql?query=SELECT+%3Fp+%3Fo%0D%0AWHERE+{%0D%0A<http%3A%2F%2Fdbpedia.org%2Fresource%2FBerlin>+%3Fp+%3Fo}"
curl "http://dbpedia.org/sparql?query=SELECT ?p ?o WHERE {<http://dbpedia.org/resource/Berlin> ?p ?o}"
Interfaz HTML
Interfaz para usuarios no expertos
Navegar por los datos publicados

Resultados
Integración en nube LOD
Enlaces a otros recursos Linked Data
La capacidad de los datos de «ser descubiertos» aumenta
Los datos son más interoperables a través de
a) Uso de triple RDF (modelo de datos común)
b) Ontologías comunes («esquema» común)
c) Uso de URIs para entidades (identificadores enlazables)
Beneficios para usuarios
Acceder a datos de manera más rica a través de la web (la web son los datos, no un documento que representa los datos)
Acceder a más datos, con enlaces más ricos («es parte de», «nació en», … ) a otros recursos: descubrimiento de nuevos datos
Encontrar datos de manera más precisa
Un ecosistema más rico de Apps, ya que es más fácil desarrollar Apps que integren datos
Beneficios para desarrolladores
Crear programas nuevos fácilmente: ej. visualizaciones especificas
Analizar los datos exhaustivamente, en relación a datos externos: ej. estadísticas locales vs estadísticas a nivel europeo
Integración de datos
Descubrimiento de nuevos datos
¿Por qué publicar datos en LD?
Enlaces al exterior:
Publicar solo nuestros datos, referencias al resto, no hay que replicar datos externos
Los datos externos se actualizan independientemente, y nuestro dataset va "a remolque" sin esfuerzo
¿Por qué publicar datos en LD?
Enlaces a nuestro dataset:
Es facil enlazar a nuestro dataset, ya que usamos HTTP URIs
Por lo tanto, aumenta la capacidad de nuestro dataset de ser descubierto mediante enlaces
¿Por qué publicar datos en LD?
Semántica:
El significado de nuestro datos es explícito y claro, debido a RDF (instancias) + OWL ("esquema")
Es "fácil" crear aplicaciones, incluyendo razonamiento automático (ej. agentes)
Open Authors
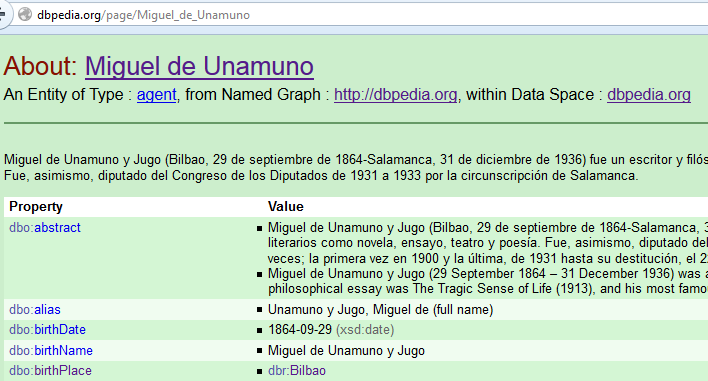
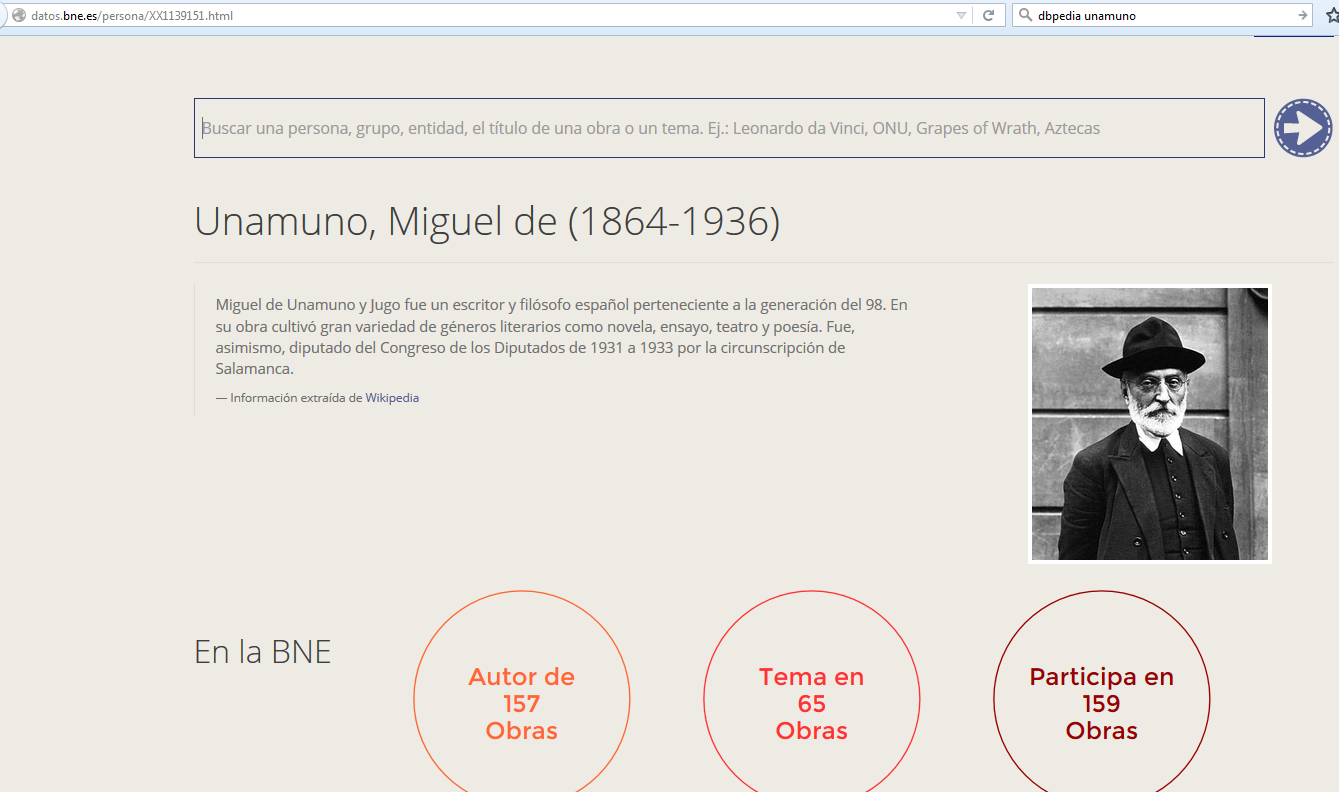
Proceso Open Authors



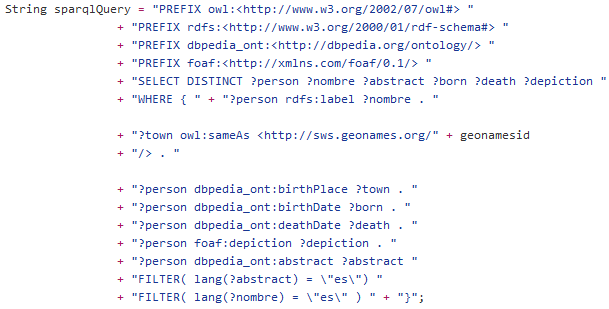
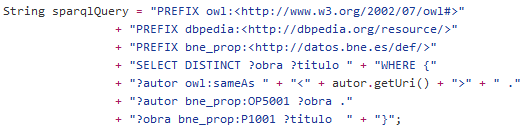
Euskal Fauna

Proceso Euskal Fauna

Integración/Limpieza
Transformar a RDF
Enlaces DBPedia

ErroldApp
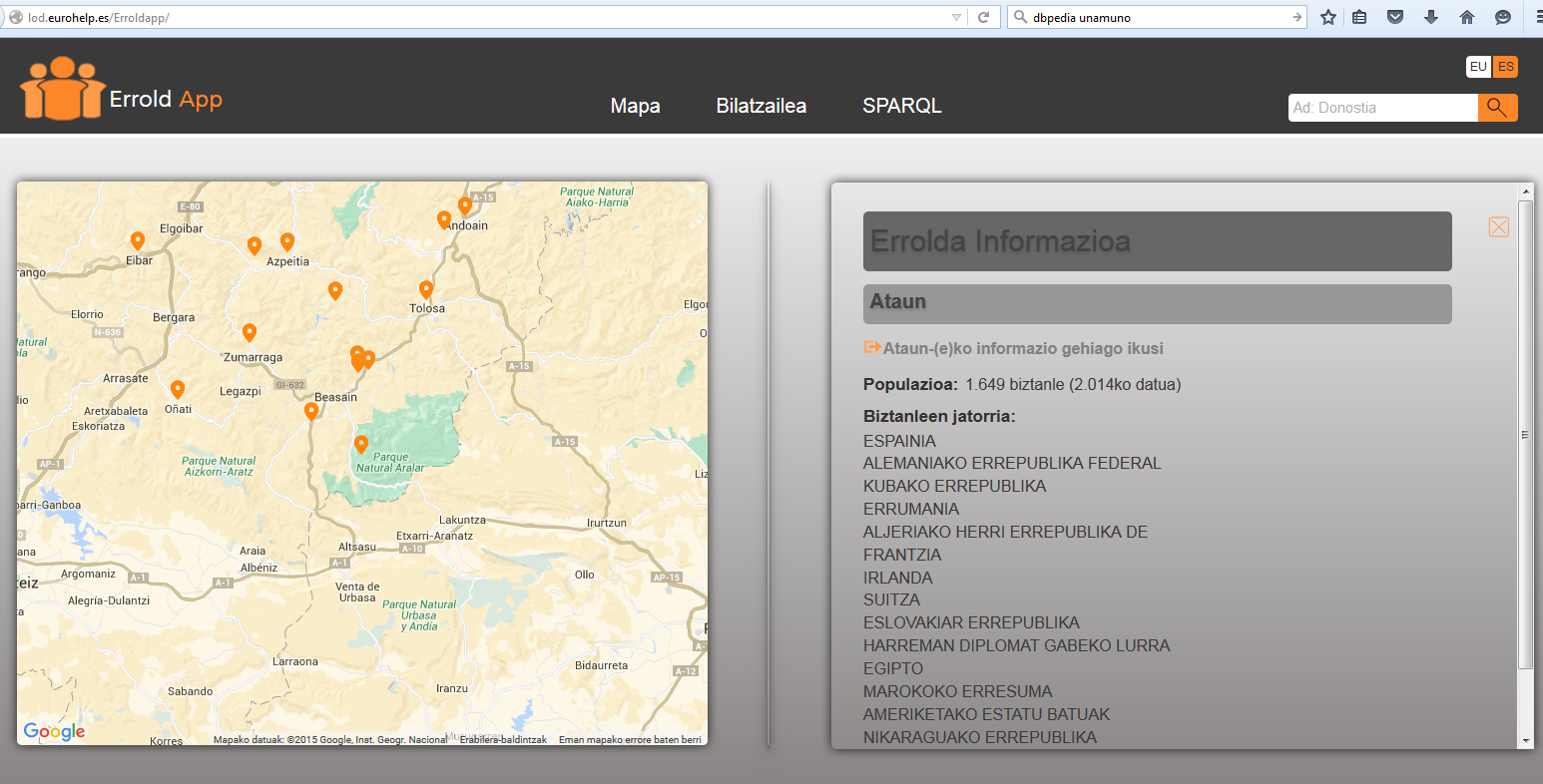
Proceso ErroldApp
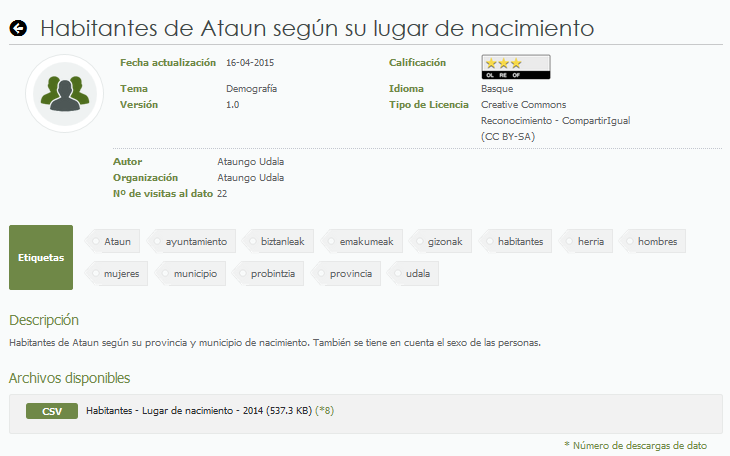
HabitantesAtaun.csv
HabitantesAtaun.rdf
HabitantesAtaun_enlaces.rdf
Open LOD Generator




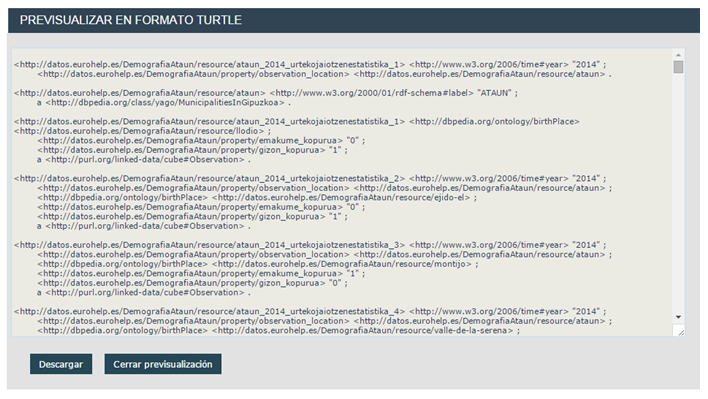








Todo el proceso de transformación/publicación en un solo servidor con varios interfaces:
- Admin/publicar RDF
- Consumir RDF: SPARQL endpoint, servidor Web, downloads, etc.
El proceso se puede detener/retomar en cualquier fase
Genera automaticamente todo lo necesario para publicación Linked Data de acuerdo a buenas practicas:
- PROV, VoID (+DCAT)
- Servidor web con negociación de contenido
- SPARQL endpoint
- Datahub
- Enlaces a Linked Open Data cloud
Obliga al usuario a añadir rdf:type, rdfs:label
Organización en temas-proyectos-archivos
Todos los datos se guardan en «named graphs»: metadatos (tema-proyecto-archivos), esqueleto usado para conversión, datos a publicar
- «Provenance» (+SPARQL): quien convirtio los datos de demografia a RDF? De donde vienen los datos de demografia de Aduna? Que reglas de conversión se uso?
- Genera VoID + DCAT más facilmente
- Modelo indep. de aplicación: exportar proyectos y datos enteros
Esqueleto reusable para diferentes datos
Integración con Linked Open Vocabularies: sugerir ontologías
Web Semántica
Web Semántica

Web Semántica



Web Semántica
Linked Data
Un primer paso hacia la Web Semántica que ya funciona
con tecnología actual (URI, HTTP, ...)

RDF
RDF (Resource Description Framework)
Triple RDF
Grafo RDF
Grafo RDF
Todas las entidades del grafo se identifican mediante URIs
URI: Uniform Resource Identifier (≠ URL!). Identifica recursos
http://gipuzkoa.eus/ataun.html#ataun http://dbpedia.org/resource/Ataun
URL: Uniform Resource Locator. Una URI que indica la localización física de un recurso en la red
http://gipuzkoa.eus/ataun.html

Grafo RDF: URIs

Grafo RDF
Los sujetos y predicados sólo pueden ser recursos (URIs)
Algunos objetos pueden ser valores literales (Cadenas de caracteres)
Los valores literales pueden tener tipo (XML Schema datatypes)
Grafo RDF: datatypes

rdf:type

Agrupar recursos en clases
RDF namespaces
RDF usa namespaces para "agrupar" URIs
Namespaces se pueden abreviar/expandir mediante prefix
PREFIX dbpedia:<http://dbpedia.org/resource/>
dbpedia:Donostia = http://dbpedia.org/resource/Donostia
dbpedia:Ataun = http://dbpedia.org/resource/Ataun
...
Vocabularios
RDF |
http://www.w3.org/1999/02/22-rdf-syntax-ns# |
RDFS |
http://www.w3.org/2000/01/rdf-schema# |
OWL |
http://www.w3.org/2002/07/owl# |
Vocabulario: informalmente, colección definida de URIs, normalmente bajo un mismo namespace
Vocabularios "reservados" (definen lenguajes)
rdf:type = http://www.w3.org/1999/02/22-rdf-syntax-ns#type
Ontologías
La mayoría de los vocabularios son ontologías
Definen propiedades generales de los datos que queremos publicar:
foaf:person dbpedia-ont:city dc:book ...
Ontologías

Prefix.cc
Linked Open Vocabularies

RDF: modelo vs sintaxis
RDF es un modelo de datos
Ese modelo abstracto se puede representar con diferentes sintaxis: "Serializar" (escribir) en un archivo
Una de esas sintaxis es RDF/XML
No confundir el modelo con la sintaxis: ¡RDF es mucho más que un archivo XML!
Serializar RDF
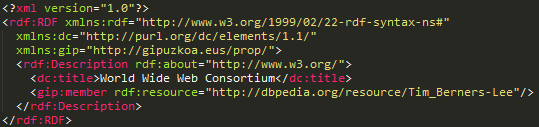
Serializar RDF: RDF/XML

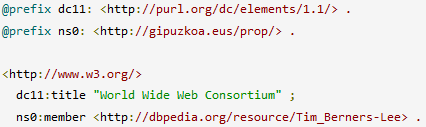
Serializar RDF: Turtle
Herramientas utiles
Ejercicio 1
Crear un archivo RDF que contenga:

Ejercicio 1
Abrir Virtual Box
Iniciar maquina virtual LOD-EJIE
[Login: lod, passwd:lod]
Abrir http://localhost en firefox
Ejercicio 1
Usar un editor cualquiera (gedit, vim, ...)
Generar en RDF/XML o TTL
Seguir ejemplos anteriores
Algunos prefix:
PREFIX gip:<http://gipuzkoa.eus/resource/>
PREFIX gip_prop:<http://gipuzkoa.eus/prop/>
PREFIX dbpedia:<http://dbpedia.org/resource/>
PREFIX rdfs: ??? [Pista: buscar en prefix.cc]
Ejercicio 1
Ejercicio 1
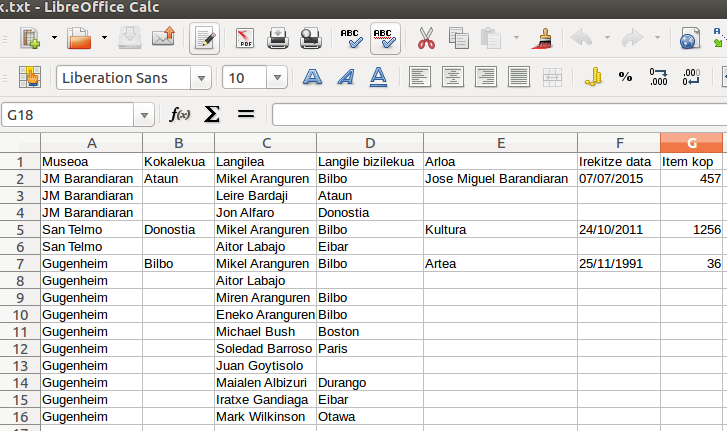
Ejercicio 2
Convertir fragmentos de Ejercicio2/Museoak a RDF
Posible solución (No hay una manera correcta!): https://github.com/mikel-egana-aranguren/LinkedOpenDataEjie2016/tree/master/Ejercicios/Ejercicio2
Ejercicio 2 (Extra)
Crear un archivo RDF/XML o TTL que contenga:
Bilbo (nuestro dataset) es igual a (owl:sameAs) "Bilbao" (DBpedia)
Solución: https://github.com/mikel-egana-aranguren/LinkedOpenDataEjie2016/tree/master/Ejercicios/Ejercicio2
SPARQL
SPARQL
Lenguaje para hacer consultas sobre grafos RDF (~"El SQL para RDF")
SPARQL
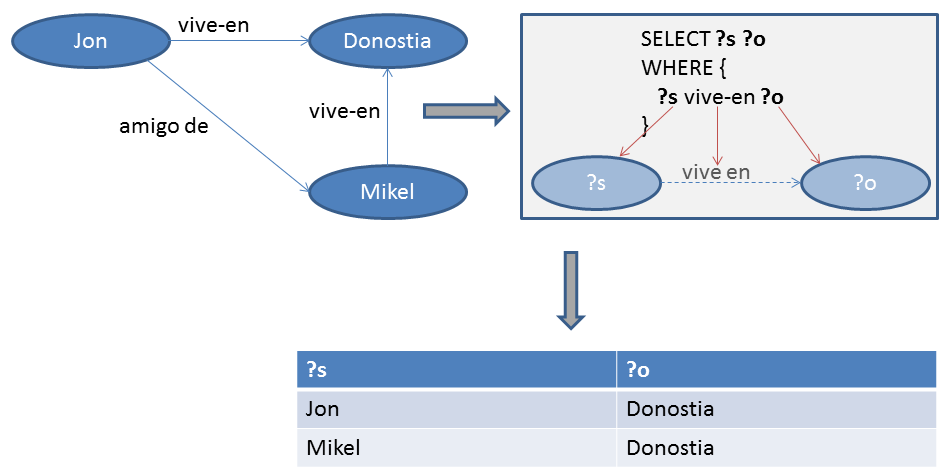
SELECT ?s ?o
WHERE {
?s vive_en ?o
}SPARQL

SPARQL
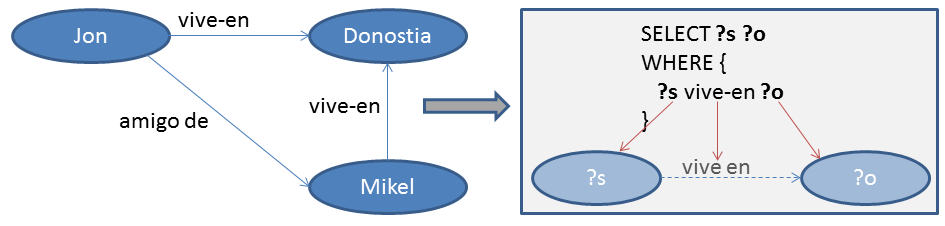
SPARQL
Ejecutar triple store (LinkedDataServer/blazegraph):
java -server -jar blazegraph.jar
Subir archivo (Ejercicio3/jon-mikel.ttl) a triple store:
Update >> choose file
Ejercicio 3
¿Consulta para obtener todos los triples de un grafo?
¿Quién vive en un sitio y tiene un amigo? [Pista: SPARQL se basa en Turtle]
Soluciones: https://github.com/mikel-egana-aranguren/LinkedOpenDataEjie2016/tree/master/Ejercicios/Ejercicio3
Ejercicio 3
Estructura de consulta
# Prefixes PREFIX gip_prop: <http://gipuzkoa.eus/prop/> PREFIX gip: <http://gipuzkoa.eus/resource/> # Variables que queremos recibir SELECT ?sujeto ?clase # Patrón del grafo que queremos extraer del grafo mayor WHERE { ?sujeto gip_prop:bizilekua gip:donostia . ?sujeto rdf:type ?clase }
[Subir Ekercicio2/Museoak.rdf a triple store]
Estructura de consulta
# Prefixes PREFIX gip_prop: <http://gipuzkoa.eus/prop/> PREFIX gip: <http://gipuzkoa.eus/resource/> # Queremos recibir todas las variables SELECT * # Patrón del grafo que queremos extraer del grafo mayor WHERE { ?sujeto gip_prop:bizilekua gip:donostia . ?sujeto rdf:type ?clase }
Optional
PREFIX gip_prop: <http://gipuzkoa.eus/prop/> PREFIX gip: <http://gipuzkoa.eus/resource/> PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#> PREFIX foaf: <http://xmlns.com/foaf/0.1/> SELECT ?langile ?bizilekua WHERE { # Tiene que ser una persona ?langile rdf:type foaf:person . # Tiene que vivir en algun sitio ?langile gip_prop:bizilekua ?bizilekua }
Optional
PREFIX gip_prop: <http://gipuzkoa.eus/prop/> PREFIX gip: <http://gipuzkoa.eus/resource/> PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#> PREFIX foaf: <http://xmlns.com/foaf/0.1/> SELECT ?langile ?bizilekua WHERE { # Tiene que ser una persona ?langile rdf:type foaf:person . # Puede vivir en un sitio o no OPTIONAL { ?langile gip_prop:bizilekua ?bizilekua } }
Union
PREFIX foaf: <http://xmlns.com/foaf/0.1/> PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#> SELECT ?entitatea ?izena WHERE { {?entitatea rdfs:label ?izena } UNION {?entitatea foaf:name ?izena } }
Ordenar resultados
PREFIX foaf: <http://xmlns.com/foaf/0.1/> PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#> SELECT ?pertsona ?izena WHERE { ?pertsona foaf:name ?izena }
ORDER BY DESC (?izena) # Puede ser DESC o ASC
Limitar resultados
PREFIX foaf: <http://xmlns.com/foaf/0.1/> PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#> SELECT ?pertsona ?izena WHERE { ?pertsona foaf:name ?izena }
ORDER BY DESC (?izena) LIMIT 3
"Paginación"
PREFIX foaf: <http://xmlns.com/foaf/0.1/> PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#> SELECT ?pertsona ?izena WHERE { ?pertsona foaf:name ?izena }
ORDER BY DESC (?izena) LIMIT 3 OFFSET 3
"Paginación"
PREFIX foaf: <http://xmlns.com/foaf/0.1/> PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#> SELECT ?pertsona ?izena WHERE { ?pertsona foaf:name ?izena }
ORDER BY DESC (?izena) LIMIT 3 OFFSET 6
Filtrar resultados
PREFIX gip_prop: <http://gipuzkoa.eus/prop/> SELECT ?museoa ?langile_kop WHERE { ?museoa gip_prop:kopurua ?langile_kop . FILTER (?langile_kop > "800"^^xsd:int) }
Filtrar resultados
SELECT ?langile ?izena WHERE { ?langile foaf:name ?izena . FILTER regex(?izena,'Mi.*') }
Filtrar resultados
Logica: !, &&, ||
Calculos: +, -, *, /
Comparaciones: =, !=, >,<
Tests SPARQL: isURI, isBlank, isLiteral, bound
Acceder a datos: str, lang, datatype
Más: sameTerm, langMatches, regex, ...
Evitar duplicados
SELECT ?lantokia
WHERE {
?person rdf:type foaf:person .
?person <http://vocab.data.gov/def/drm#worksFor> ?lantokia
}
SELECT DISTINCT ?lantokia
WHERE {
?person rdf:type foaf:person .
?person <http://vocab.data.gov/def/drm#worksFor> ?lantokia
}
ASK
PREFIX gov:<http://vocab.data.gov/def/drm#> PREFIX gip:<http://gipuzkoa.eus/resource/> ASK WHERE { ?person gov:worksFor gip:gugenheim }
DESCRIBE
DESCRIBE <http://gipuzkoa.eus/resource/mikel-aranguren>
CONSTRUCT
PREFIX gip_prop:<http://gipuzkoa.eus/prop/> PREFIX gip:<http://gipuzkoa.eus/resource/> PREFIX gov:<http://vocab.data.gov/def/drm#> CONSTRUCT { ?langile rdf:type gip:gugenheim_langilea } WHERE { ?langile gov:worksFor gip:gugenheim }
DELETE DATA
DELETE DATA {
<http://gipuzkoa.eus/resource/aitor-labajo> rdf:type foaf:person
}
[Pestaña "Update" en Blazegraph, seleccionar "SPARQL update"]
DESCRIBE <http://gipuzkoa.eus/resource/aitor-labajo>
DELETE
DELETE {?person rdf:type foaf:person}
WHERE {?person foaf:name ?name}
SELECT *
WHERE {
?person rdf:type foaf:person
}
INSERT DATA
PREFIX gip:<http://gipuzkoa.eus/resource/>
INSERT DATA {
gip:aitor-labajo rdf:type gip:hiritar
}
[Pestaña "Update" en Blazegraph, seleccionar "SPARQL update"]
DESCRIBE <http://gipuzkoa.eus/resource/aitor-labajo>
INSERT
PREFIX gip:<http://gipuzkoa.eus/resource/> INSERT { gip:jon-alfaro rdf:type ?type . } WHERE { gip:aitor-labajo rdf:type ?type . }
[Pestaña "Update" en Blazegraph, seleccionar "SPARQL update"]
DESCRIBE <http://gipuzkoa.eus/resource/jon-alfaro>
Consultas federadas
PREFIX owl: <http://www.w3.org/2002/07/owl#> PREFIX dbpedia_ont: <http://dbpedia.org/ontology/> PREFIX gip: <http://gipuzkoa.eus/resource/> SELECT ?poblacion_bilbo WHERE { gip:bilbo owl:sameAs ?town SERVICE <http://dbpedia.org/sparql> { ?town dbpedia_ont:populationTotal ?poblacion_bilbo } }
[Subir Ejercicio2/bilbo_dbpedia.ttl a blazegraph]
GRAFOS
Grafo: conjunto de triples
El conjunto entero se identificada con una URI (diferente de la de los datos)
Todas las Triple Stores tienen un Default Graph
GRAFOS

GRAFOS
Los grafos son muy utiles para añadir datos sobre los datos: ej. procedencia, autoria, fecha de generación
(entre otras cosas)
GRAFOS

GRAFOS
PREFIX dc: <http://purl.org/dc/elements/1.1/>
PREFIX ns: <http://example.org/ns#>
INSERT DATA{
GRAPH <http://example/bookStore> {
<http://example/book1> ns:price 42
}
}
[Pestaña "Update" en Blazegraph, seleccionar "SPARQL update"]
GRAFOS
SELECT *
FROM <http://example/bookStore>
WHERE {?s ?p ?o}
SELECT *
FROM <http://example/bookStore>
WHERE {?s ?p ?o}
Ejercicio 4
¿Qué museo tiene trabajadores cuyo nombre empieza por "Mi" y más de 800 trabajadores?
[Pista: FILTER, &&]
Solucion: https://github.com/mikel-egana-aranguren/LinkedOpenDataEjie2016/tree/master/Ejercicios/Ejercicio4
Ejercicio 5
¿Donde se situa el museo en el que trabaja Aitor Labajo?
Ejercicio 6
¿Quien es el alcalde de la ciudad en la que se situa el museo gugenheim? [Pista: owl:sameAs, SERVICE]
OWL
OWL
OWL (Web Ontology Language) es un estándar oficial del W3C para crear ontologías en la web con un semántica precisa y formal
OWL
OWL se basa en Lógica Descriptiva (DL)
Representación computacional de un dominio de conocimiento:
Razonamiento automático: inferir conocimiento "nuevo" (*), consultas, consistencia, clasificar entidades contra la ontología, ...
Integrar conocimiento disperso
Sintaxis
Para ordenadores: RDF/XML, OWL/XML, ...
Para humanos: Manchester OWL Syntax, functional, ...


Semántica
Una ontología OWL esta compuesta de:
-
Entidades: las entidades del dominio de conocimiento, identificadas con URIs, introducidas por el desarrollador ("Mikel", "participa_en", ...)
-
Axiomas: relacionan las entidades mediante el vocabulario lógico que ofrece OWL (namespace OWL)
Una ontología puede importar otra (owl:import) y hacer referencia a sus entidades mediante axiomas
Entidades
Entidades (URI)
Axiomas
("URI OWL")
Individuos
Clases
Propiedades
Objeto
Datos
Anotación
Ontologia
(URI)
Entidades
Entidad
Axioma
EuskalHiria subClassOf kokapena some EuskalProbintzia
Clase
Clase
Propiedad objeto
Restricción
Individuos

[Fuente de imagenes: Manchester OWL Pizza tutorial]
Propiedades
Clases
Clases

Clase subclase

Clases equivalentes

Jerarquía de clases (Taxonomía)

Condiciones necesarias

Condiciones necesarias y suficientes

Restricción existencial

Restricción universal
Restricción un individuo (value)

Restricciones cardinales

Más axiomas
disjointFrom
booleanos: not, or, and

Expresiones complejas

Propiedades

Jerarquía Propiedades
Jerarquía propiedad-subpropiedad (~taxonomía pero con propiedades), ej:
-
interacciona con
-
mata a
estrangula a
-
Propiedades

Propiedades

Propiedades

Propiedades datos
Solo funcional
Dominio clases, rango datatypes
Propiedades anotación
Anotar con lenguaje natural entidades (propiedades, clases, individuos), axiomas, ontologías
Fuera de la semántica
rdfs:label, rdfs:comment, dublin core, a medida
Individuos
Miembro de una o más clases (Types)
Igual (SameAs) o diferente (DifferentFrom) a otro individuo
Relaciones binarias con otros individuos o datos (triples), positivas o negativas
Razonamiento automático
Un razonador infiere los "nuevos" axiomas que implican los axiomas que hemos introducido en la ontología
El razonador infiere todos los axiomas; es útil para tratar con conocimiento complejo
Open World Assumption (OWA)
(Falta de) Unique Name Assumption (¡owl:sameAs!)
Razonamiento automático
Mantener taxonomía

Razonamiento automático
Consistencia

Razonamiento automático
Clasificar entidades: dada una entidad nueva, como se relaciona con las demas entidades (types, equivalentTo, subClassOf, triples)
Una consulta es una clase anónima que clasificamos contra la ontología como si fuese una entidad
Ejercicio/Ejemplo 7
Crear una ontología con que haga referencia a los datos de museos
Ejecutar Protege: /protege/./run.sh
Crear ontologia nueva
Ontology IRI: http://gipuzkoa.eus/admin_ontology.owl
Preference entities URI: http://gipuzkoa.eus/ont/
Importar museoak-rdf-owl.rdf
Ejercicio/Ejemplo 7
langilea equivalentTo worksFor some museum
inferencia
langilea2 equivalentTo worksFor min 2 museum
inferencia
???
Ejercicio/Ejemplo 7
bilbotarlangilea equivalentTo worksFor some museum and bizilekua value Bilbo
Inferencia
worksFor o kokalekua = bizilekua
Inferencia
BilbotarLangilea
Ejercicio/Ejemplo 7
bilbo kokalekua Euskadi
euskalplace equivalentTo kokalekua value Euskadi
Inferencia
Bilbo?
Gugenheim?
Linked Data
Linked Data
1.- Usar URIs para identificar entidades
2.- Usar URIs HTTP para que se pueda acceder a esas entidades
3.- Cuando un usuario o agente accede a una URI, proveer información útil mediante estándares (RDF)
4.- Incluir enlaces a otras URIs para que se puedan descubrir más entidades
Linked Data
Grafos y triple stores
Un "triple store" contiene diferentes grafos

Grafos y triple stores
Solo recibiremos los triples de ese triple store ...
¡Pero nosotros o nuestro agente automático podemos seguir los enlaces! ("Follow your nose")
URIs/URLs en Linked Data
URI identifica a entidad; URLs localizan diferentes representaciones (RDF, HTML, ...) de la entidad
Descripción de la entidad (RDF, HTML, ...) ≠ entidad
HTTP URI dereferenciable: cuando se busca una URI, deberia devolver una descripción adecuada del objeto que identifica esa URI
Negociación contenido

Negociación contenido

Negociación contenido

curl -L -H "Accept: text/html" "http://dbpedia.org/resource/Berlin"
curl -L -H "Accept: application/rdf+xml" "http://dbpedia.org/resource/Berlin"
curl -L -H "Accept: text/html" "http://sws.geonames.org/2950159/"
curl -L -H "Accept: application/rdf+xml" "http://sws.geonames.org/2950159/"
"303 URI" vs "# URIs"

# URI

303 URI

Diseño URIs
[http://www.slideshare.net/boricles/]
[BOE-A-2013-2380]
Base URI: http://geo.linkeddata.es/
TBox URIs:
http://geo.linkeddata.es/ontology/{concept|property}
http://geo.linkeddata.es/ontology/Provincia
ABox URIs:
http://geo.linkeddata.es/resource/{r. type}/{r. name}
http://geo.linkeddata.es/resource/Provincia/Madrid
Publicar datos LD
1) Crear el dataset
Ontología OWL: reusar lo más posible de otras ontologías para interoperabilidad
Instancias RDF (triples)
2) Añadir enlaces a otros datasets
Manualmente o con herramientas como SILK, LIMES, Refine, ...
A nivel de instancias (owl:sameAs, predicados, ...) y a nivel de vocabulario (owl:equivalentClass, ...)
Publicar datos LD
3) Almacenar el dataset en triple store
4) Publicar el dataset mediante servidor web

Publicar datos LD
Publicar datos LD

Publicar datos LD
Ejercicio 8
Recrear todo el proceso de publicar nuestro dataset Linked Data en nuestro servidor, en una infraestructura ya preparada (Linked Data Server)
Ejecutar blazegraph, subir Museoak.rdf y bilbo_dbpedia.ttl
Ejecutar jetty (pubby)
$ cd /jetty $ java -jar start.jar jetty.port=8080
Linked Data
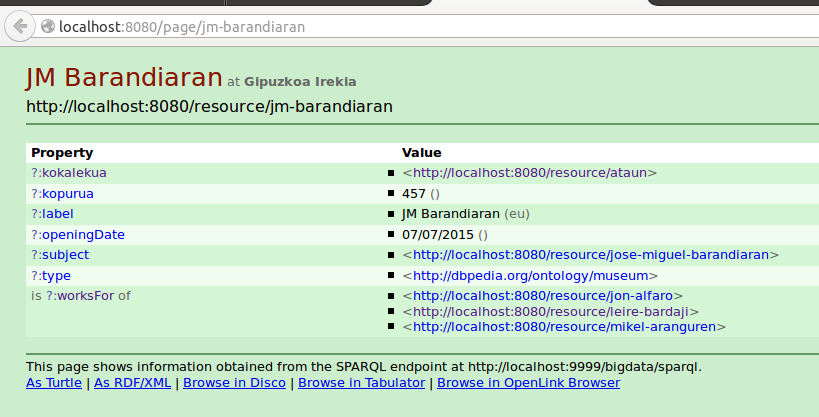
Linked Data
Negociación de contenido en terminal:
$ curl -L "http://localhost:8080/resource/jm-barandiaran" $ curl -L -H "Accept: application/rdf+xml" http://localhost:8080/resource/jm-barandiaran
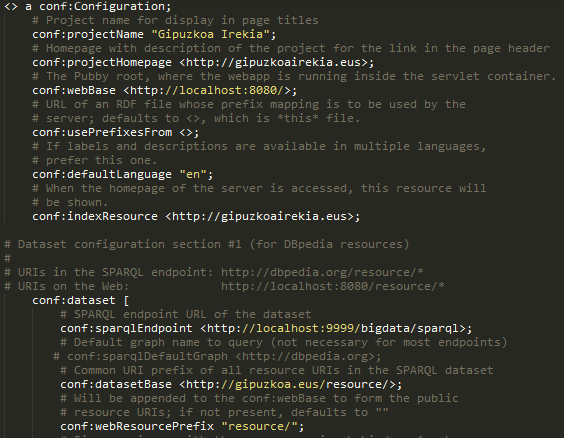
Configuracion Pubby
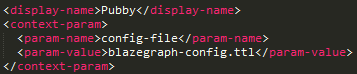
jetty/webapps/ROOT/WEB-INF/web.xml
jetty/webapps/ROOT/WEB-INF/blazegraph-config.ttl
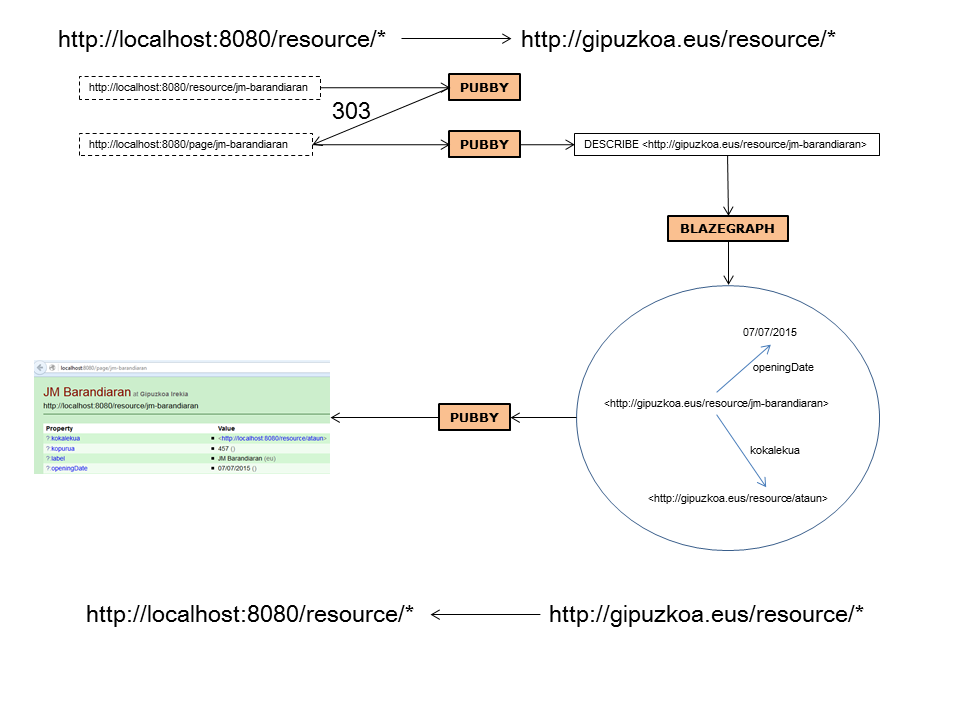

Ejercicio 9
Crear un dataset nuevo (pocos triples), con URIs propias, y publicarlo
Subir a blazegraph; Configurar pubby