Life Sciences Semantic Web (LSSW)
Máster Bioinformática UM (2013-2014)
Mikel Egaña Aranguren
http://mikeleganaaranguren.com / mikel.egana.aranguren@gmail.com
Life Sciences Semantic Web (LSSW)
http://mikeleganaaranguren.wordpress.com/teaching/
Versión HTML de esta presentación
Todo el material (Presentación, ejercicios, datos, código) en GitHub

Life Sciences Semantic Web
Life Sciences Semantic Web
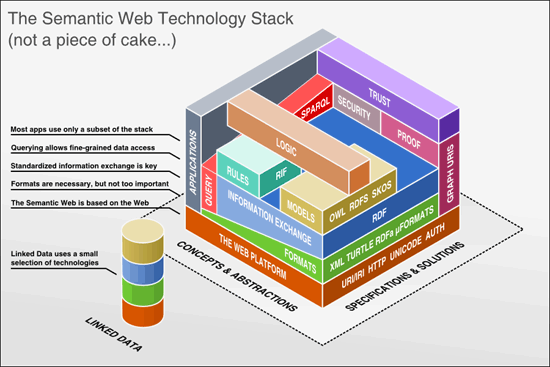
Pila tecnologías Web Semántica
Ontologías
bio-ontologías
Open Biological and Biomedical Ontologies (OBO)
OBO Foundry: Open, Common shared syntax, Unique identifier space, Versions, Delineated content, Definitions, OBO Relation Ontology, Well documented, Users, Collaboratively
Gene Ontology
Vocabulario controlado para describir la función molecular, el componente celular y el proceso biológico de genes (“Gene Products”)
Integración de información (GAF files), explotación estructura (ej. Term Enrichment)
OBO
ChEBI, Cell Type, Sequence Ontology, Phenotype Ontology, UberOntology, ...
"Meta-Ontologías": Basic Formal Ontology (BFO), OBO Relation Ontology (RO)
Mucho contenido de relativamente alta calidad pero ...
... la mayoría de las ontologías son muy pobres axiomáticamente
... OBO format (*)
OBO format

ONTO-PERL
API para trabajar con ontologías OBO (y OWL*) en Perl
http://search.cpan.org/dist/ONTO-PERL/
ONTO-PERL: Ejercicio 1
Crear un script que devuelva los genes de Arabidopsis thaliana que están anotados en el arbol ciclo celular (GO:0007049) de Gene Ontology
(Usar los archivos /ejercicios/onto-perl/gene_association.tair y /ejercicios/onto-perl/go.obo)
ONTO-PERL: Ejercicio 2
Crear un script que, dados los terminos de GO GO:0030685 y GO:0000800, obtenga los ancestros comunes de ambos
(Usar /ejercicios/onto-perl/go.obo)
Ontologías en Galaxy

Ontologías en Galaxy: Ejercicio 1
Usando onto-toolkit, encontrar los genes de Arabidopsis thaliana que están anotados en el arbol ciclo celular (GO:0007049) de Gene Ontology, y crear un workflow
(Subir los archivos /ejercicios/onto-perl/gene_association.tair y /ejercicios/onto-perl/go.obo)
(Hay que eliminar las lineas que empiezan por "!" del archivo gene_association.tair y convertir los tabs a columnas)
Ontologías en Galaxy: Ejercicio 2
Usando onto-toolkit, encontrar los ancestros comunes de GO GO:0030685 y GO:0000800, y crear un workflow
(http://biomaster.atica.um.es:8080)
(Subir los archivos /ejercicios/onto-perl/gene_association.tair y /ejercicios/onto-perl/go.obo)
Ontologías en Galaxy: Ejercicio 3
Identificar que terminos GO tienen en comun las proteinas JUN (UniProt ID: P05412) y FOS (UniProt ID: P01100) y crear un workflow
(http://biomaster.atica.um.es:8080)
(Obtener las proteinas mediante BioMart y luego usar onto-toolkit)
(Copiar go.obo en una historia nueva)
OWL (Web Ontology Language)
OWL
OWL es un estándar oficial del W3C para crear ontologías en la web con un semántica precisa y formal
OWL
OWL se basa en Lógica Descriptiva (DL)
Representación computacional de un dominio de conocimiento:
- Razonamiento automático: inferir conocimiento "nuevo" (*), consultas, consistencia, clasificar entidades contra la ontología, ...
- Integrar conocimiento disperso
Sintaxis OWL
Para ordenadores: RDF/XML, OWL/XML, ...

Para humanos: Manchester OWL Syntax, functional, ...

Semántica OWL
Una ontología OWL esta compuesta de:
- Entidades: las entidades del dominio de conocimiento, identificadas con URIs, introducidas por el desarrollador ("proteina", "participa_en", ...)
- Axiomas: relacionan las entidades mediante el vocabulario lógico que ofrece OWL
Una ontología puede importar otra (owl:import) y hacer referencia a sus entidades mediante axiomas
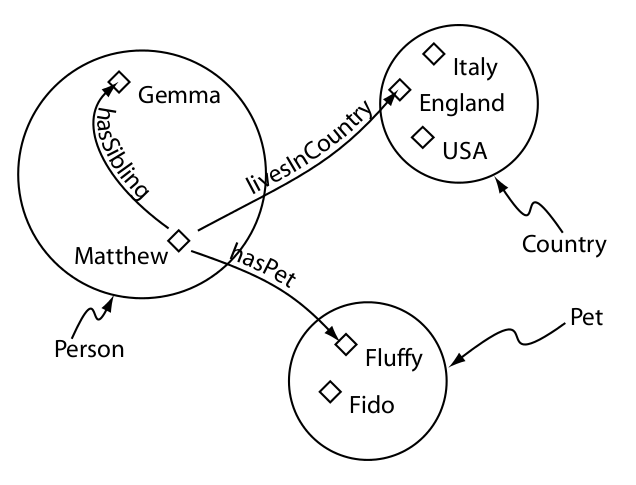
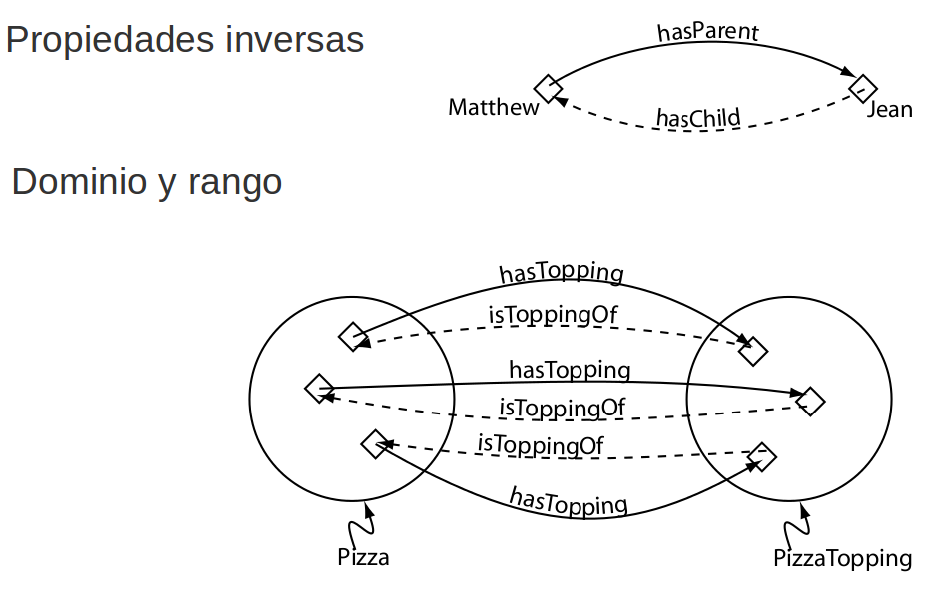
Entidades OWL
- Individuos
- Clases
- Propiedades
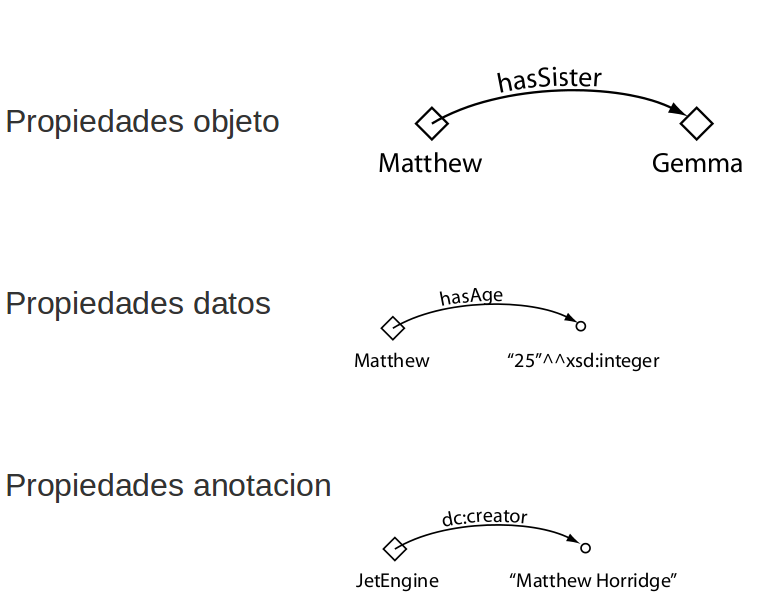
- Objeto
- Anotación
- Datos
Individuos
Propiedades
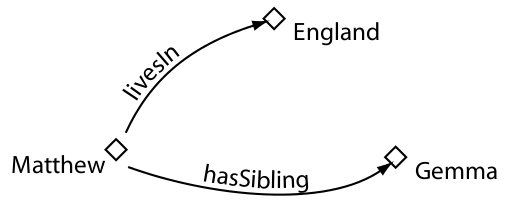
Clases
Semántica OWL
Una ontología OWL formada por individuos y clases es una "Base de Conocimiento" (KB) formada por:
- TBox (Terminological Box): clases (~ "esquema")
- Abox (Assertional Box): individuos (~ "datos")
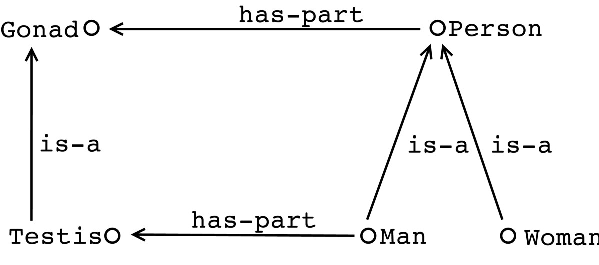
Clases
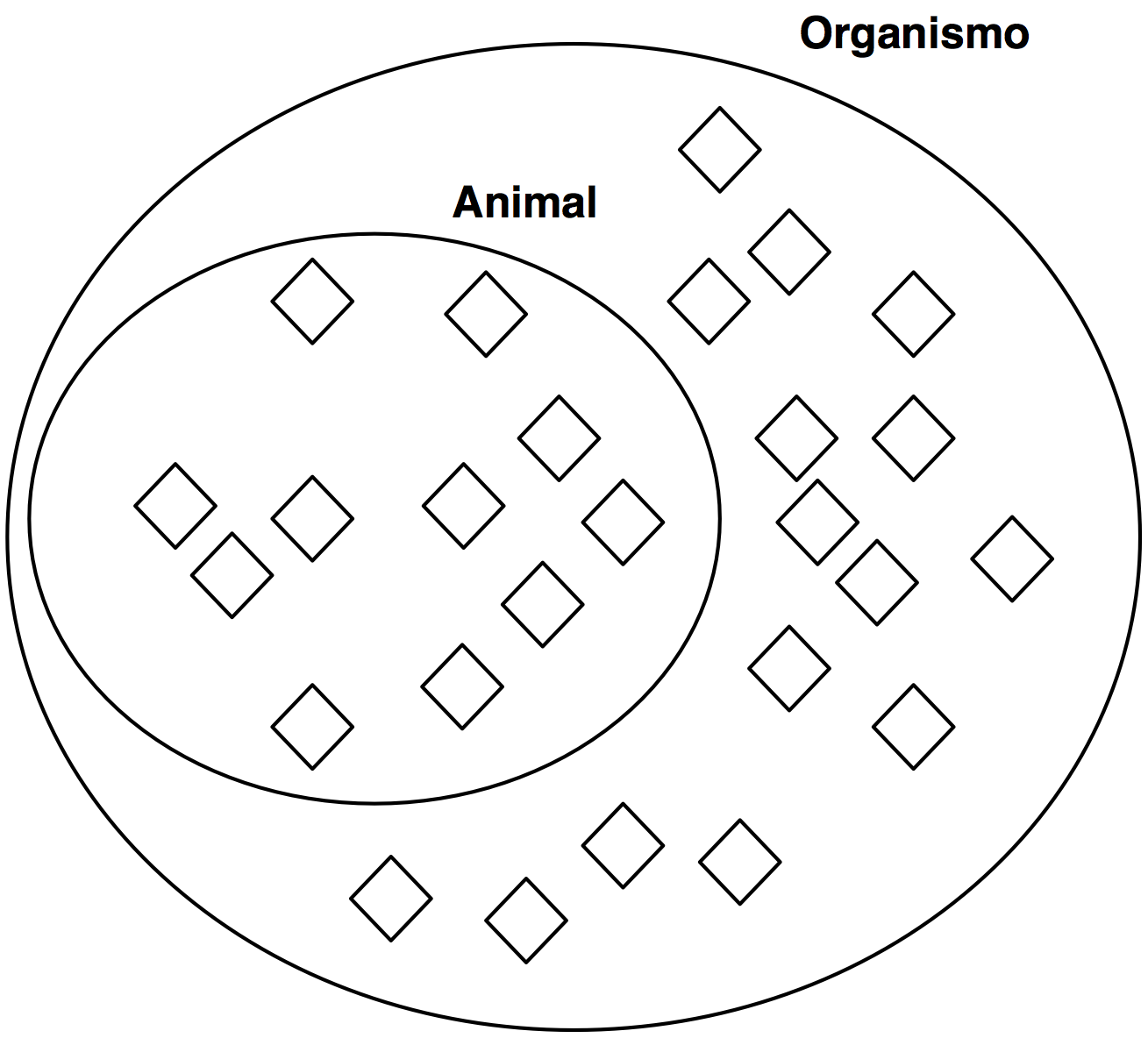
Clase subclase
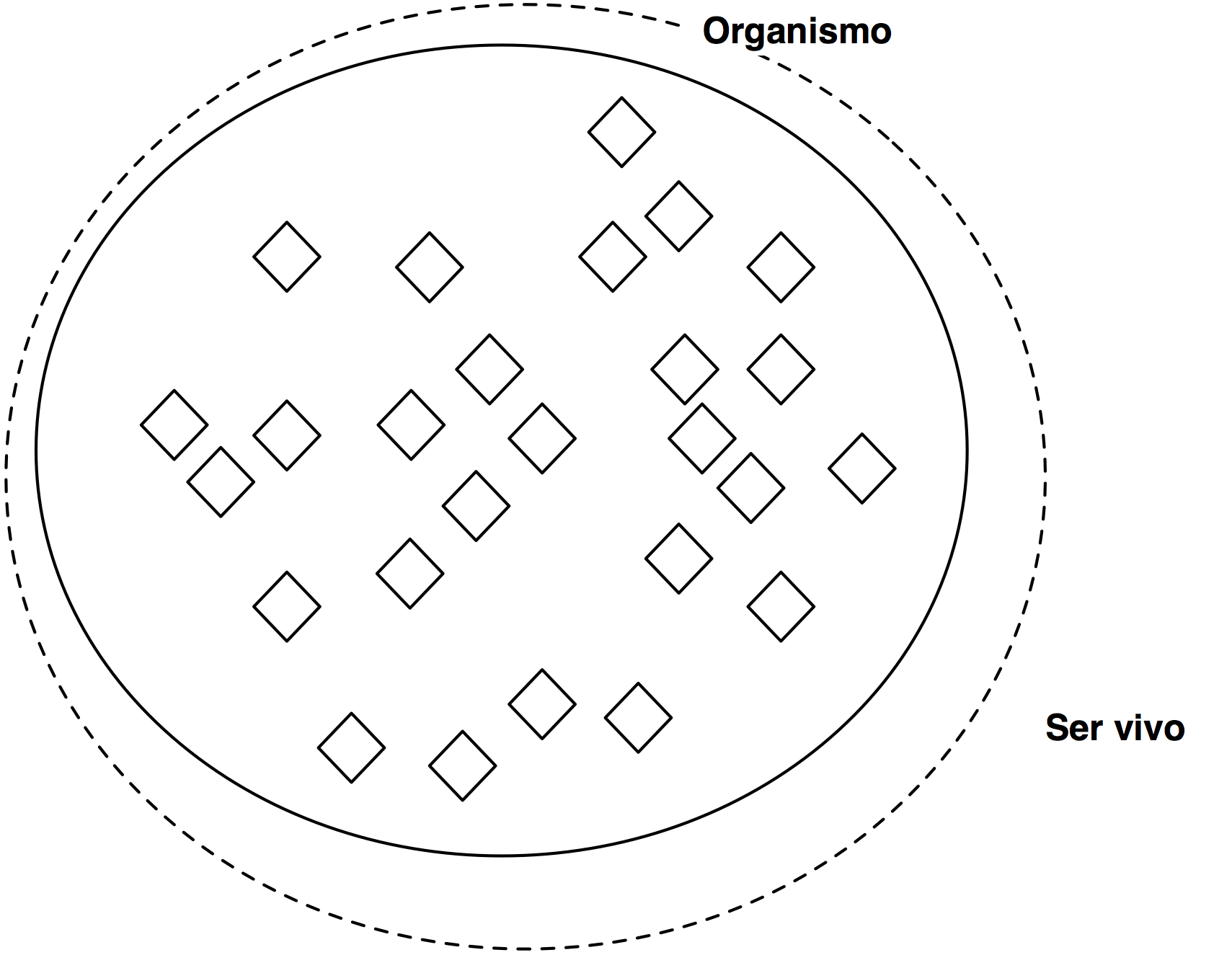
Clases equivalentes
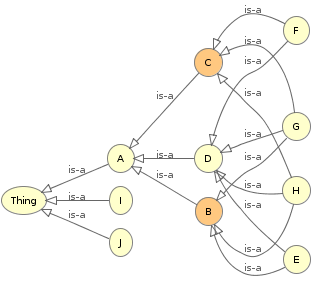
Jerarquía de clases (Taxonomía)
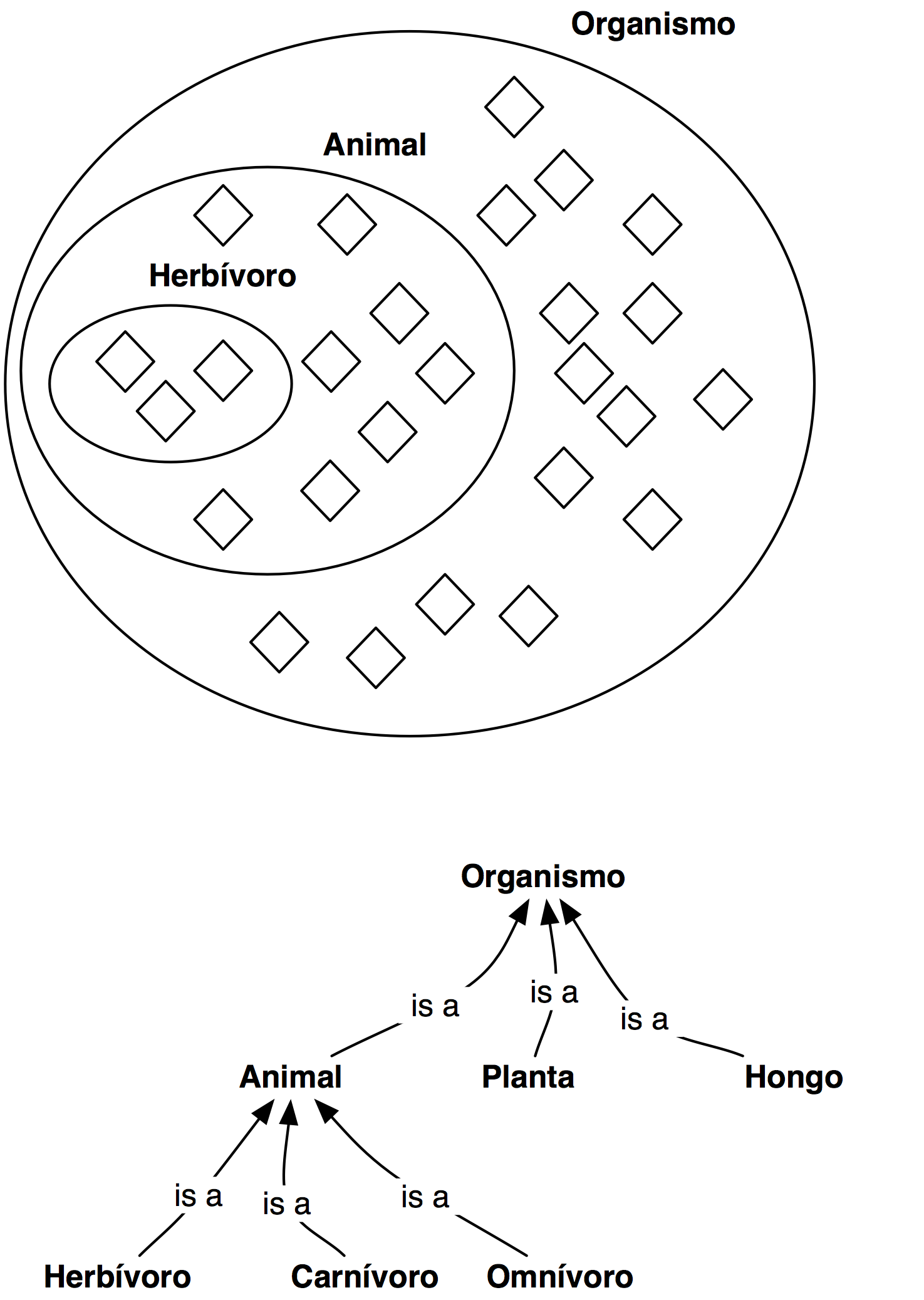
Condiciones necesarias
Condiciones necesarias y suficientes
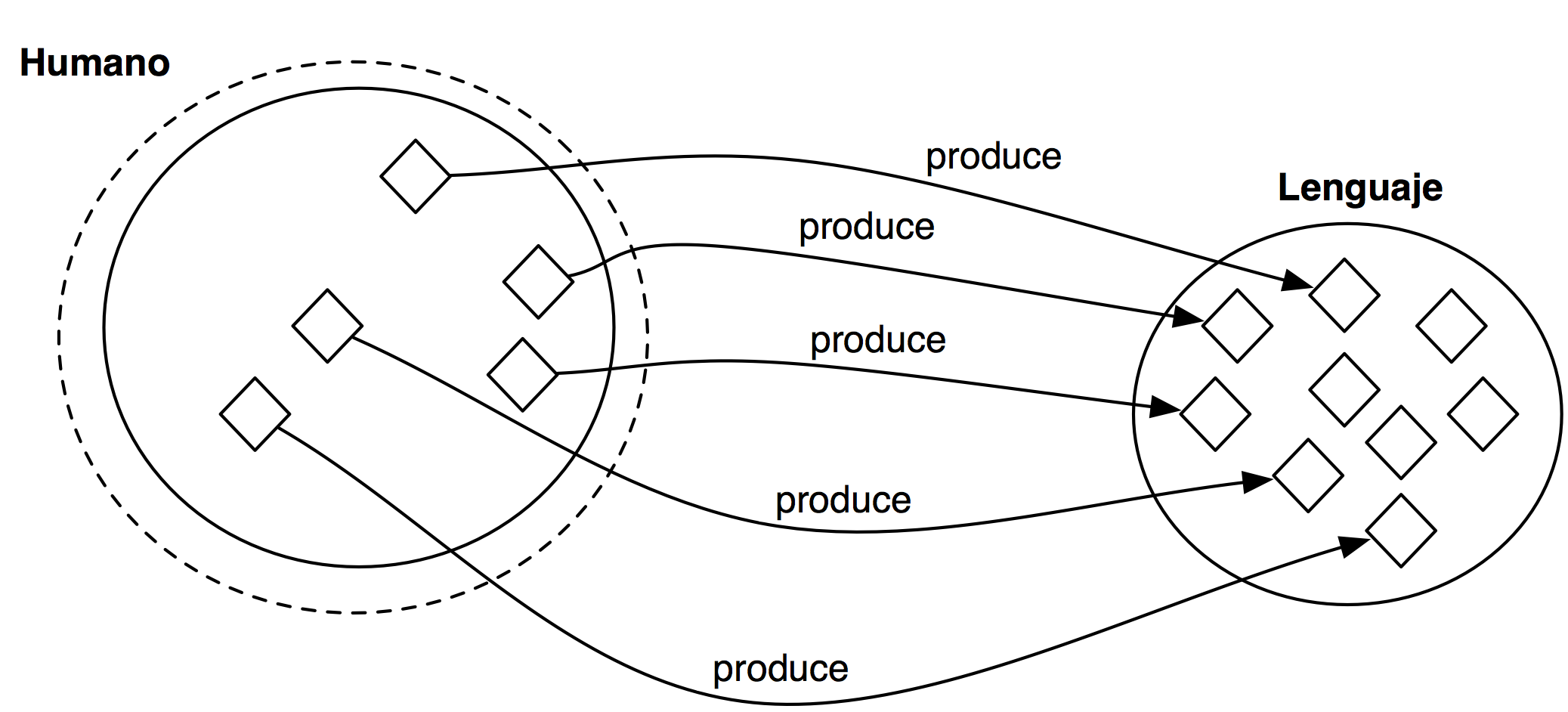
Restricción existencial (some)
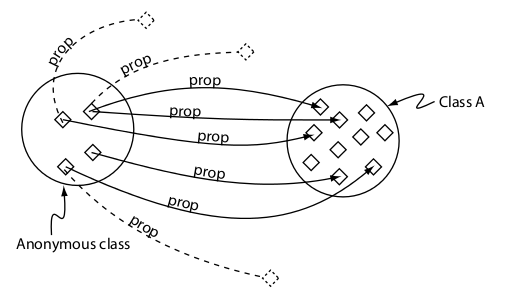
Restricción universal (only)
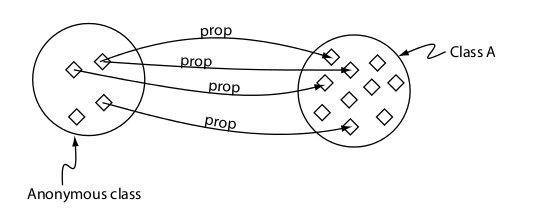
Restricción a un individuo (value)
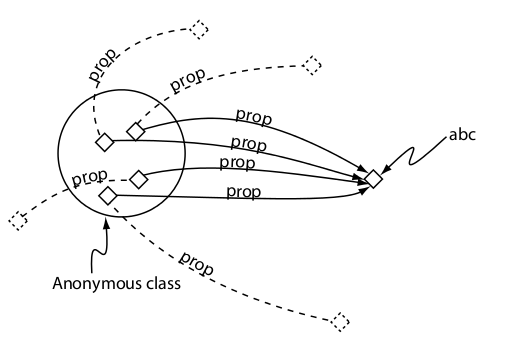
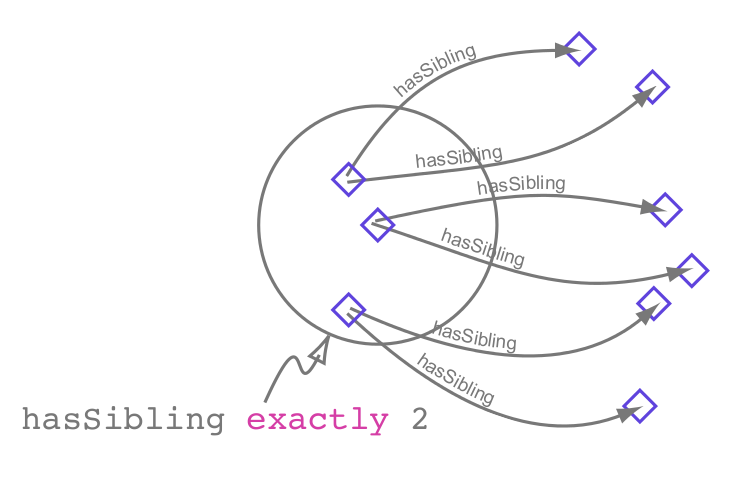
Restricciones cardinales
(+ QCR!) Manchester tutorial
Más axiomas para clases
disjointFrom
booleanos: not, or, and
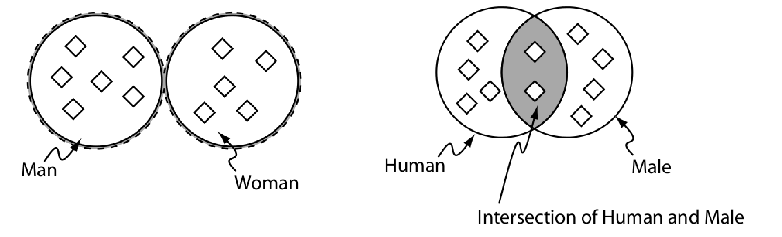
Expresiones complejas
Propiedades OWL
Jerarquía propiedades
Jerarquía propiedad-subpropiedad (~taxonomía pero con propiedades), ej:
- interacciona con
- mata a
- estrangula a
- mata a
Características propiedades objeto
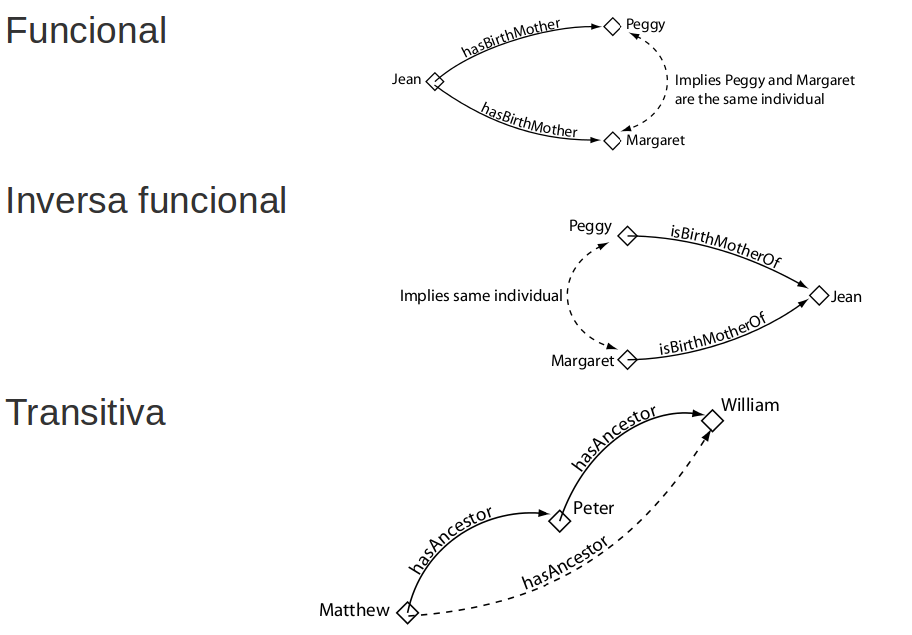
Características propiedades objeto
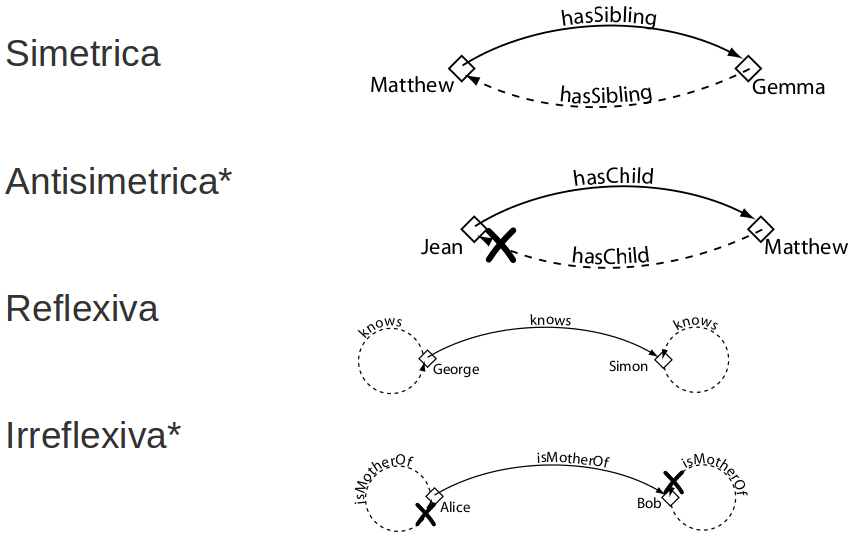
Características propiedades objeto
Características propiedades datos
Solo funcional
Dominio clases, rango datatypes
Propiedades anotación
Anotar con lenguaje natural entidades (propiedades, clases, individuos), axiomas, ontologías
Fuera de la semántica
rdfs:label, rdfs:comment, dublin core, a medida
Individuos
Miembro de una o más clases (Types)
Igual (SameAs) o diferente (DifferentFrom) a otro individuo
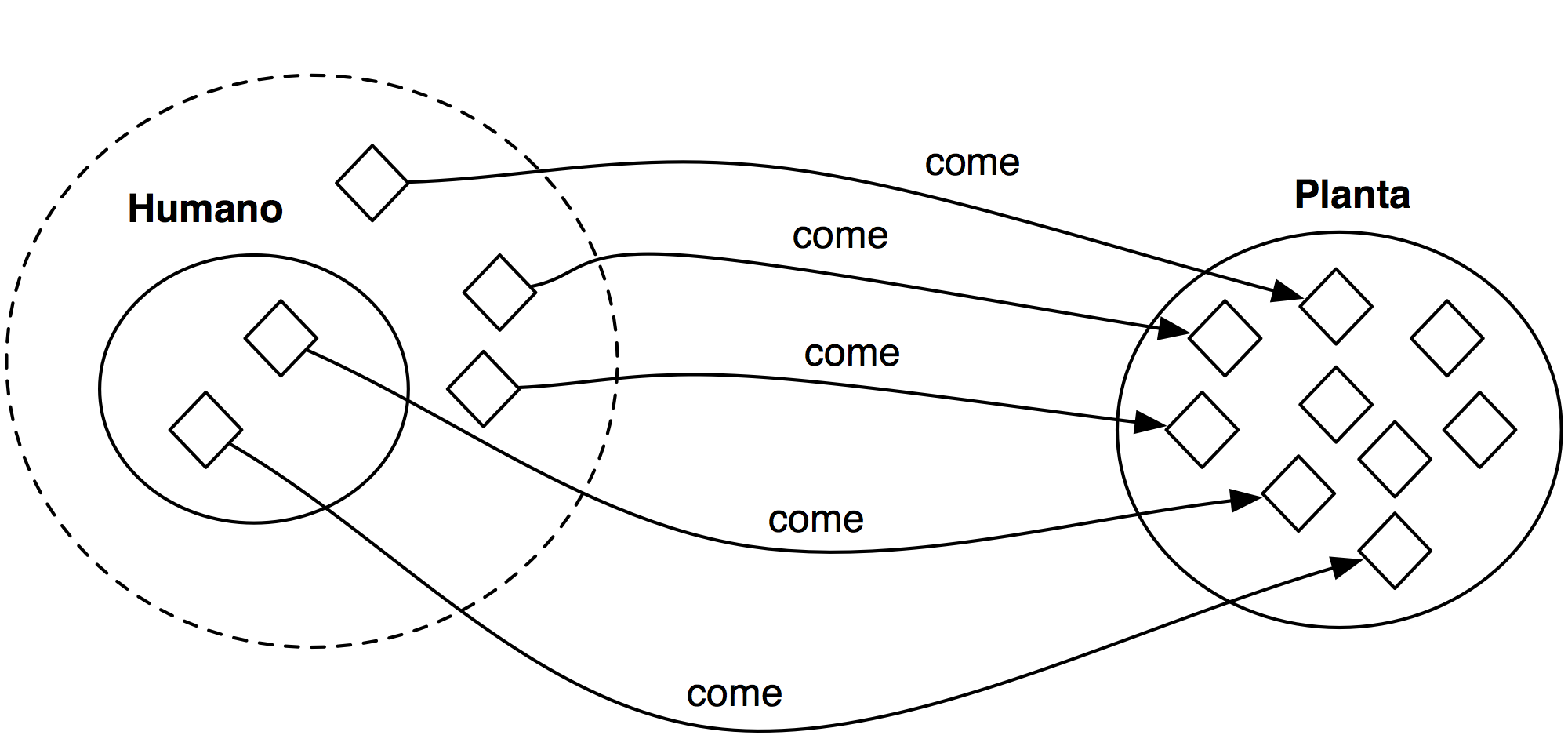
Relaciones binarias con otros individuos o datos (triples), positivas o negativas
Razonamiento automático
Un razonador infiere los "nuevos" axiomas que implican los axiomas que hemos introducido en la ontología
El razonador infiere todos los axiomas; es útil para tratar con conocimiento complejo
Open World Assumption (OWA)
(Falta de) Unique Name Assumption (¡owl:sameAs!)
Tareas más comunes razonamiento automático
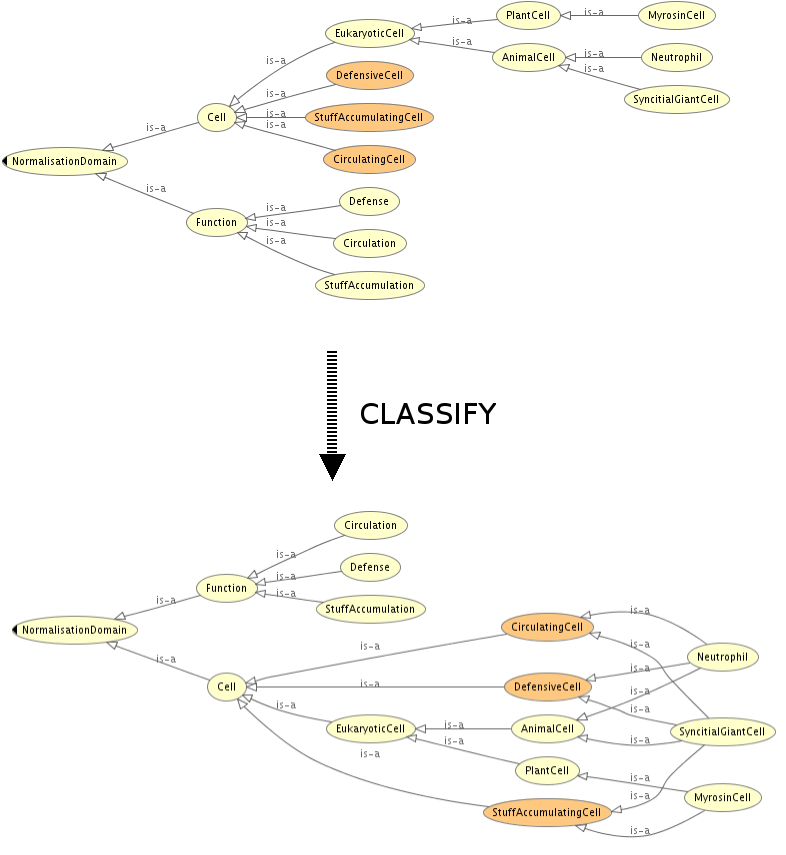
Mantener taxonomía
Consistencia
Clasificar entidades y consultas
Mantener una taxonomía
Consistencia
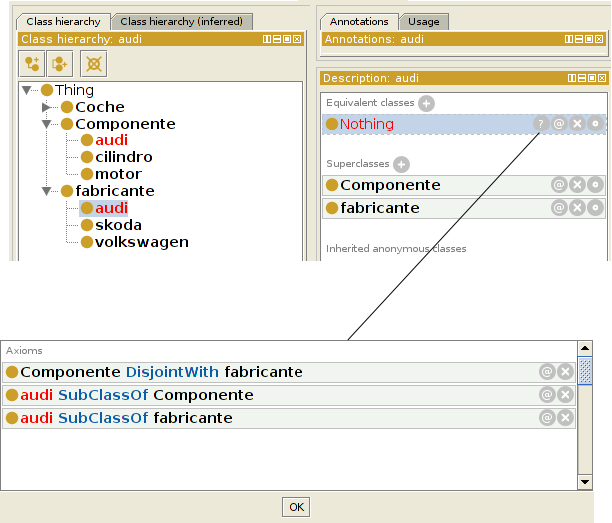
Clasificar entidades, consultas
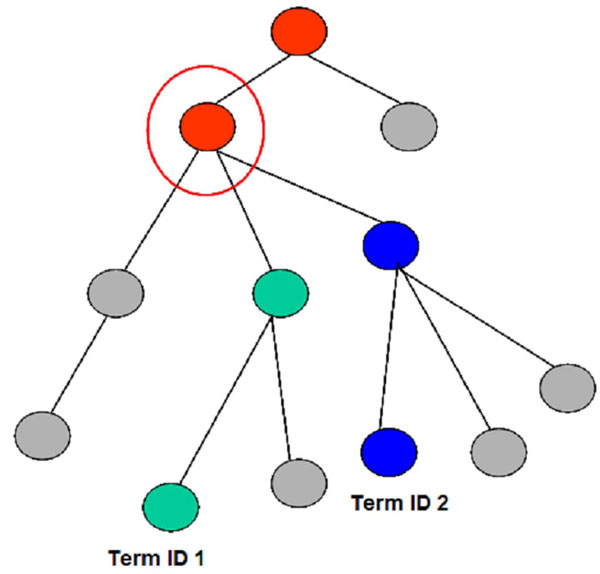
Clasificar entidades: dada una entidad nueva, como se relaciona con las demas entidades (types, equivalentTo, subClassOf, triples)
Una consulta es una clase anónima que clasificamos contra la ontología como si fuese una entidad
Ejercicios
Ejercicios: owl_assignment.pdf
Soluciones:
{kind=link}
OWL API
http://owlapi.sourceforge.net/
http://github.com/owlcs/owlapi
RDF
RDF (Resource Description Framework)
RDF es un estándar oficial del W3C para representar información en la web
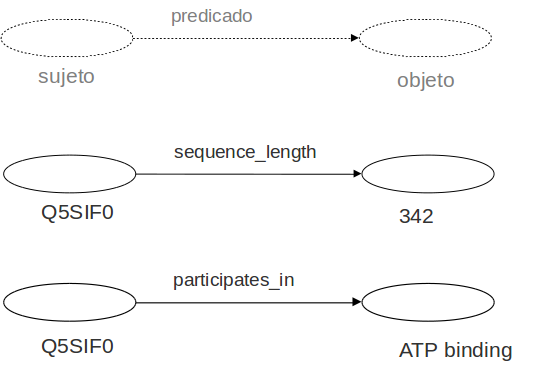
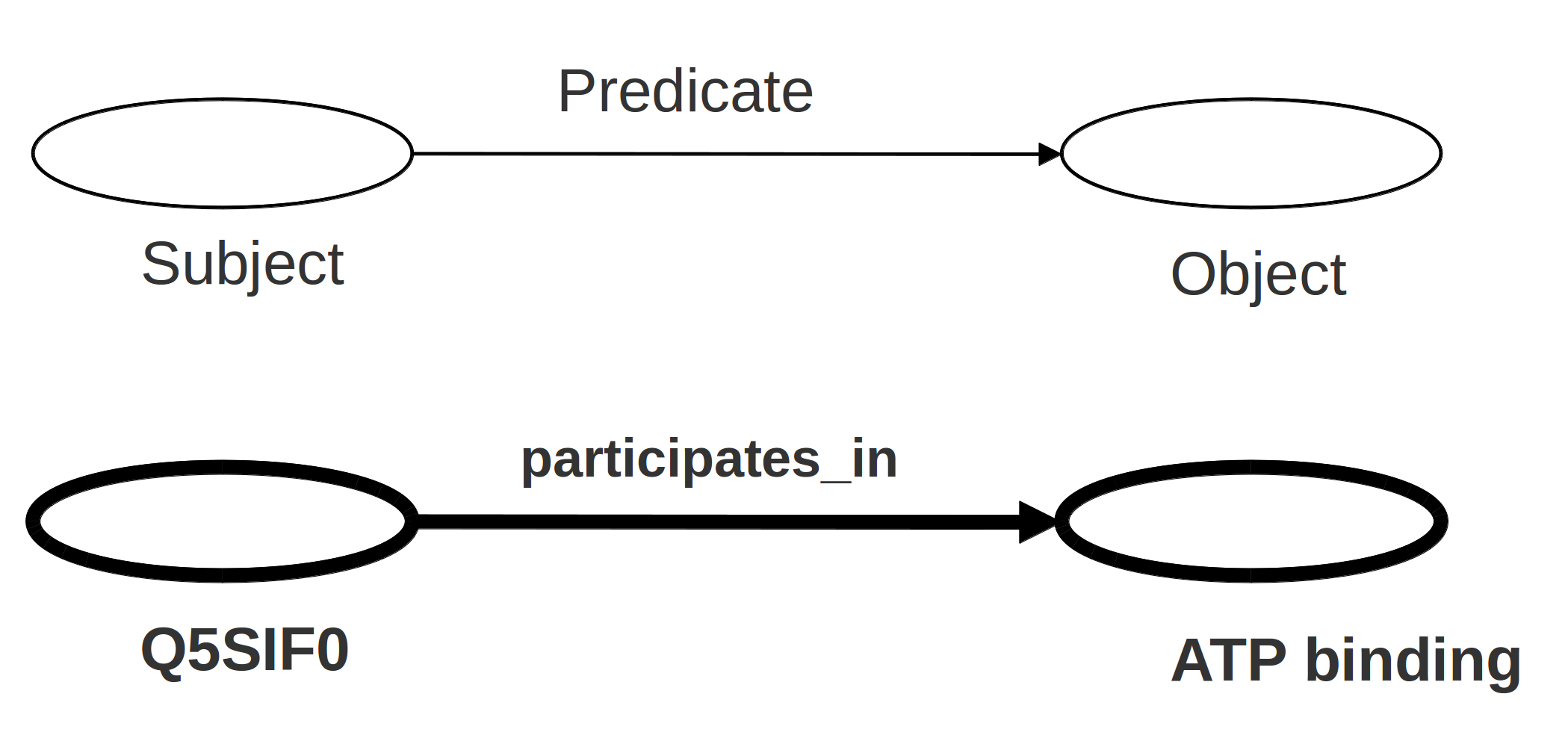
Triple RDF
Grafo RDF
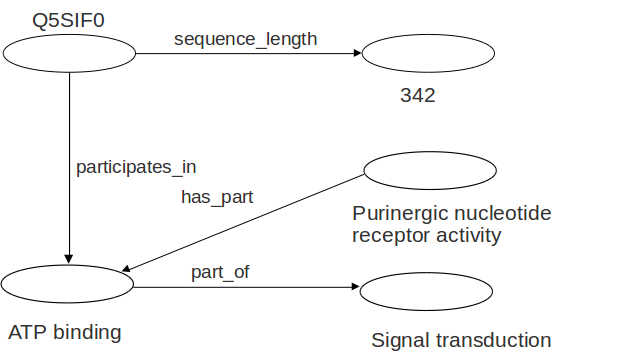
Un grafo RDF es un conjunto de triples
Grafo RDF
Algunos objetos pueden ser valores literales (Cadenas de caracteres)
Sujetos y predicados sólo pueden ser recursos
Los valores literales pueden tener tipo (XML Schema datatypes)
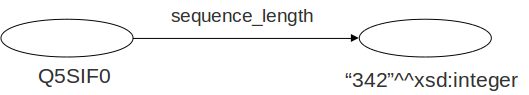
Elementos RDF
rdf:type: agrupar recursos en clases
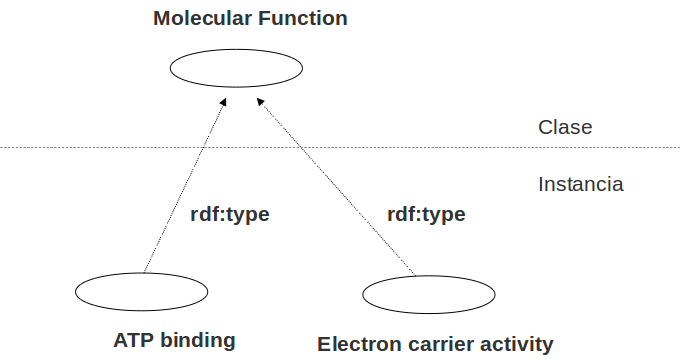
Elementos RDF

URIs en RDF
Cada recurso (Sujeto, predicado, objeto) tiene una URI
URI: Uniform Resource Identifier (RFC3986)
Espacios de nombres XML
RDF usa espacios de nombres XML mediante "qualified names"
Vocabulario: URIs bajo un espacio de nombre
- rdfs="http://www.w3.org/2000/01/rdf-schema#"
- obo="http://purl.org/obo/owl/GO#"
- owl="http://www.w3.org/2002/07/owl#"
- ...
Serializar RDF
RDF es un modelo para representar datos
Ese modelo abstracto se puede representar con diferentes sintaxis: "Serializar" (escribir) en un archivo
Una de esas sintaxis es RDF/XML
No confundir el modelo con la sintaxis: ¡RDF es mucho más que un archivo XML!
Serializar RDF
- RDF/XML (http://www.w3.org/TR/rdf-syntax-grammar/)
- RDFa (http://www.w3.org/TR/rdfa-core/)
- Turtle (http://www.w3.org/TR/turtle/)
- N3 (http://www.w3.org/DesignIssues/Notation3.html)
- ...
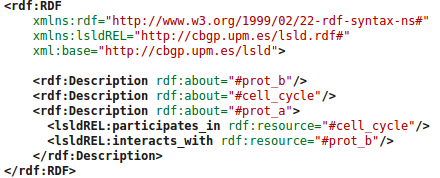
Serializar RDF: RDF/XML

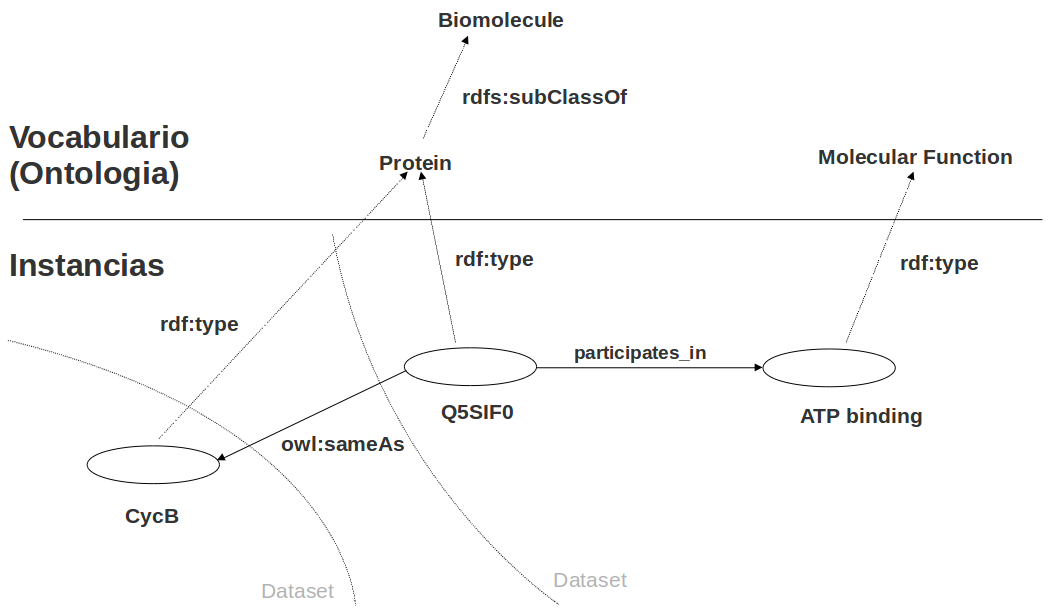
Vocabulario (ontología) / triples
Más información
SPARQL
SPARQL
Lenguaje para hacer consultas sobre grafos RDF (~"El SQL para RDF")
http://www.w3.org/standards/techs/sparql
SPARQL
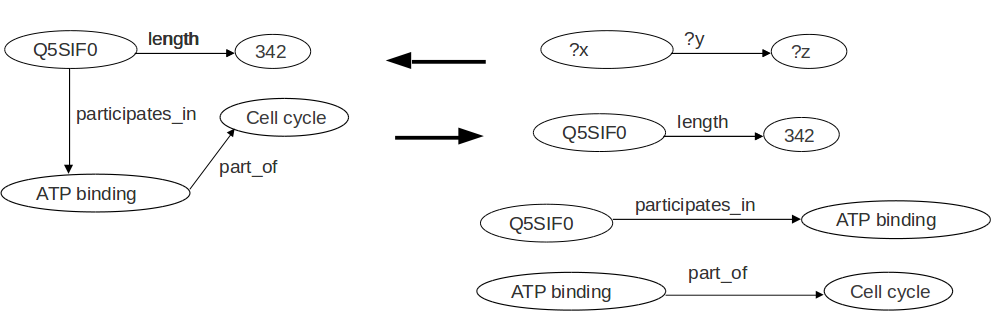
SPARQL
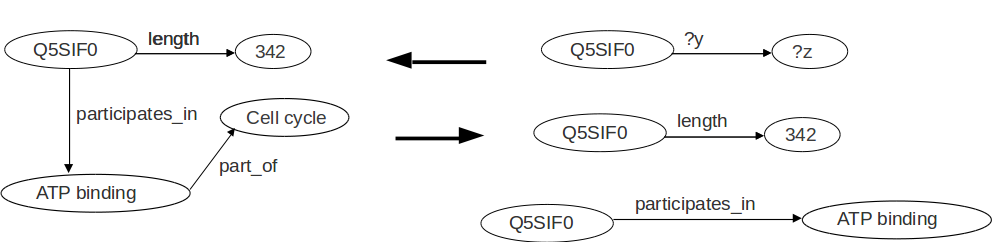
SPARQL
Tutorial: SPARQL by example (Cambridge Semantics)
SPARQL
Ejercicio práctico: http://linkedlifedata.com/sparql
SPARQL queries federadas
Get all protein catabolic processes (and more specific) in biomodels
SELECT ?go ?label
WHERE {
service <http://bioportal.bio2rdf.org/sparql> {
?go rdfs:label ?label .
?go rdfs:subClassOf ?tgo .
?tgo rdfs:label ?tlabel .
FILTER regex(?tlabel, "^protein catabolic process")
}
service &lhttp://biomodels.bio2rdf.org/sparql> {
?x &lhttp://bio2rdf.org/biopax_vocabulary:identical-to> ?go .
?x a &lhttp://www.biopax.org/release/biopax-level3.owl#BiochemicalReaction> .
}
}
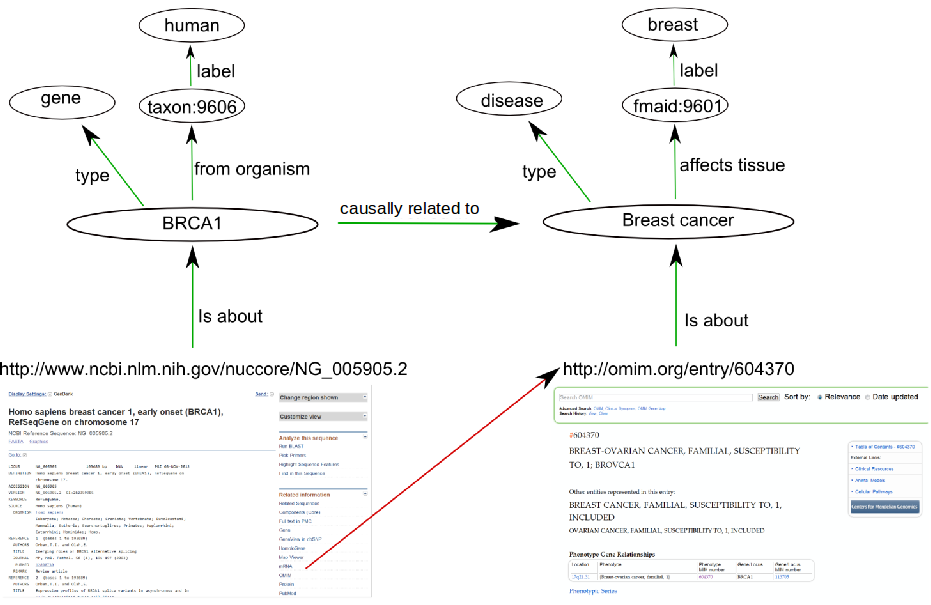
Linked Data
Video divulgativo
¿Qué es Linked Data (LD)?
Un método para ofrecer datos directamente en la web
Una propuesta del W3C: http://www.w3.org/standards/semanticweb/data
Un primer paso hacia la Web Semántica
LD utiliza la tecnología ya existente (URI, HTTP, ...) para ofrecer una primera versión de la Web Semántica
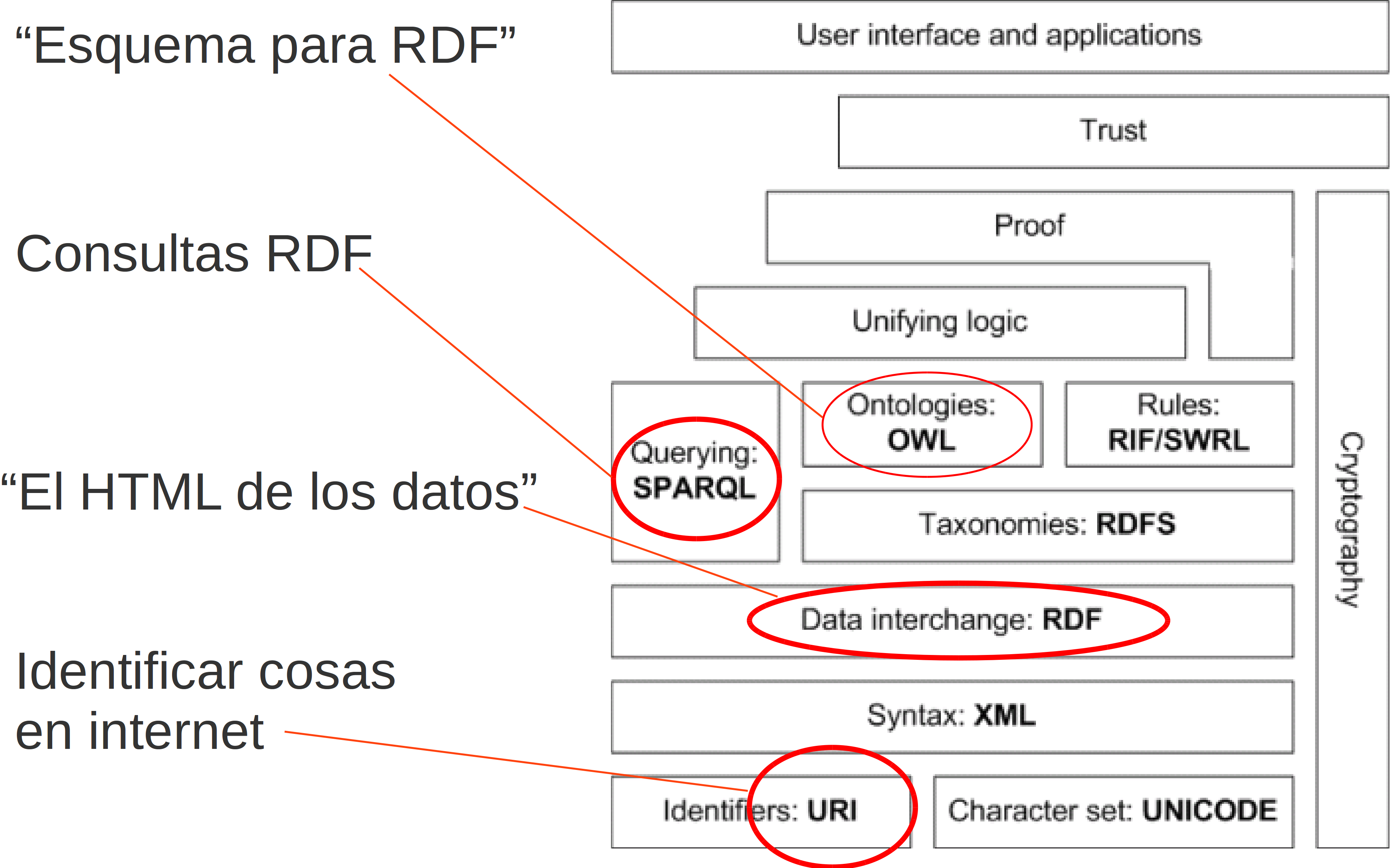
Pila tecnologías Web Semántica y LD
Principios LD
- Usar URIs para identificar entidades
- Usar URIs HTTP para que se pueda acceder a esas entidades
- Cuando un usuario o agente accede a una URI, proveer información útil mediante estándares (RDF, SPARQL)
- Incluir enlaces a otras URIs para que se puedan descubrir más entidades
http://www.w3.org/DesignIssues/LinkedData.html
Con LD publicamos datos de manera ...
... semántica
... enlazada
Semántica
RDF ofrece el triple, un modelo de datos explícito y homogéneo: una "frase" estándar que los ordenadores pueden "entender"
Enlaces
En el triple, cada entidad (sujeto, predicado, objeto) tiene una URI que lo identifica
Los datos son enlazados a otros datos a través de la web, con enlaces explícitos

Red global de datos enlazados
Red global de datos enlazados
Internet de datos, en vez de documentos: "Base de Datos universal":
- Es más fácil construir aplicaciones que exploten los datos, incluyendo razonamiento automático
- Encontramos justo lo que buscamos: consultas directas (SPARQL) en vez de procesar texto
Red global de datos enlazados
Navegamos directamente por las datos (RDF), en vez de navegar a través de documentos que representan esos datos en lenguaje natural (HTML)
Enlazar datos nuevos es tan fácil como enlazar páginas web: crecimiento orgánico de la red
Linked Open Data (LOD) cloud

http://richard.cyganiak.de/2007/10/lod/
{kind=link}
Datasets de interés
- Bio2RDF
- OGOLOD (¡UM!)
- LinkedLifeData
- HyQue*
- ArrayExpress and Gene expression atlas*
- UniProt
- LOD cloud ...
Grafos y triple stores
Un "triple store" contiene diferentes grafos
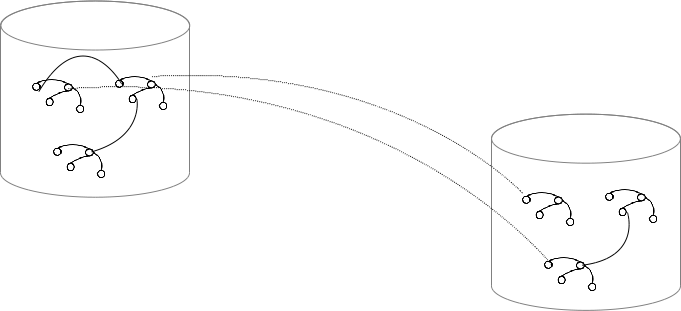
Grafos y triple stores
Solo recibiremos los triples de ese triple store (¡Pero nosotros o nuestro agente automático podemos seguir los enlaces! "Follow your nose")
URIs/URLs en Linked Data
URI identifica a la entidad; URLs identifican (localizan!) diferentes representaciones (RDF, HTML, ...) de la entidad
Descripción de la entidad (RDF, HTML, ...) ≠ entidad
HTTP URIs dereferenciable (URLs): cuando se busca una URI, deberia devolver una descripción adecuada del objeto que identifica esa URI
Negociacion contenido
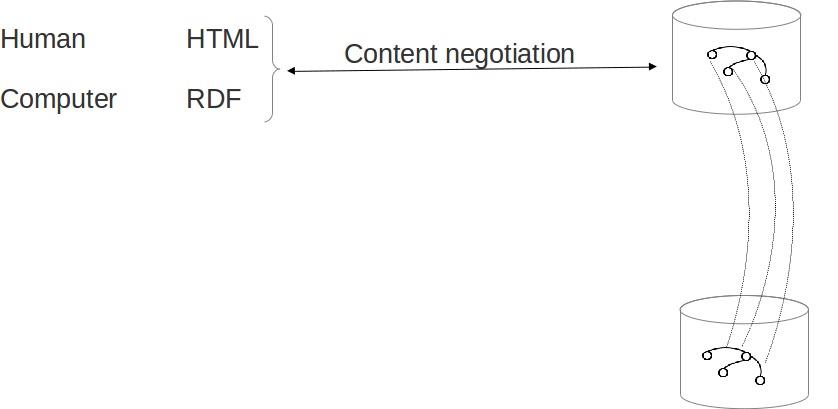
Negociacion contenido
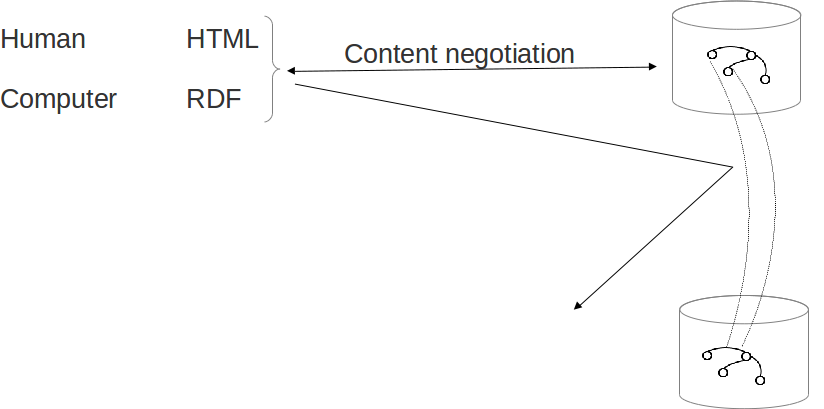
Negociacion contenido
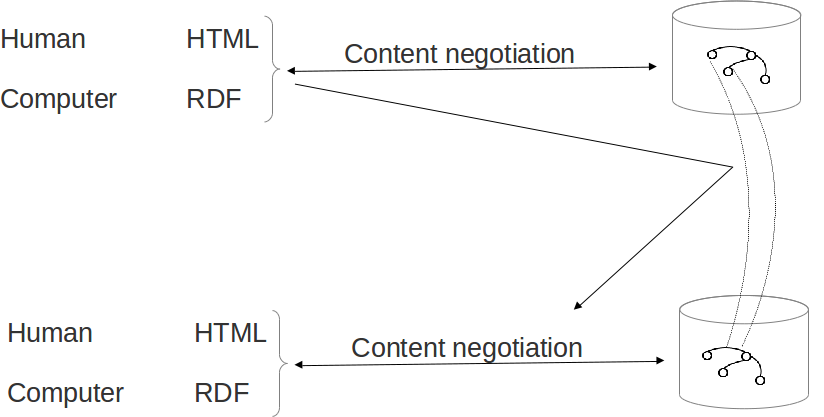
303 URIs vs Hash URIs
303 URIs
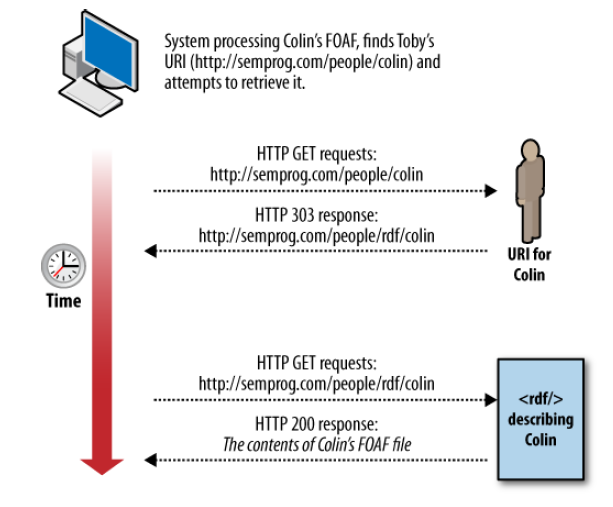
Hash URIs

Diseño URIs
- Base URI: http://geo.linkeddata.es/
- TBox URIs:
- http://geo.linkeddata.es/ontology/{concept|property}
- http://geo.linkeddata.es/ontology/Provincia
- ABox URIs:
- http://geo.linkeddata.es/resource/{r. type}/{r. name}
- http://geo.linkeddata.es/resource/Provincia/Madrid
Inferencia en LD
Para producir el dataset: materializar triples y asegurar consistencia
En consultas
Consumir LD
Navegadores LD
Buscadores LD
Aplicaciones (Mash-ups)
- Revyu
- Talis aspire
- NYT
- ...
Publicar datos en LD
¿Por qué publicar datos en LD?
- Enlaces al exterior:
- Publicar solo nuestros datos, referancias al resto, no hay que replicar datos externos:
- Los datos externos se actualizan independientemente, y nuestro dataset va "a remolque" sin esfuerzo
¿Por qué publicar datos en LD?
- Enlaces a nuestro dataset:
- Es facil enlazar a nuestro dataset, ya que usamos HTTP URIs
- Por lo tanto, aumenta la capacidad de nuestro dataset de ser descubierto mediante enlaces
¿Por qué publicar datos en LD?
Semántica: el significado de nuestro datos es explícito y claro, debido a RDF (instancias) + OWL ("esquema"): es fácil crear aplicaciones, incluyendo razonamiento automático (ej. agentes)
Publicar datos en LD
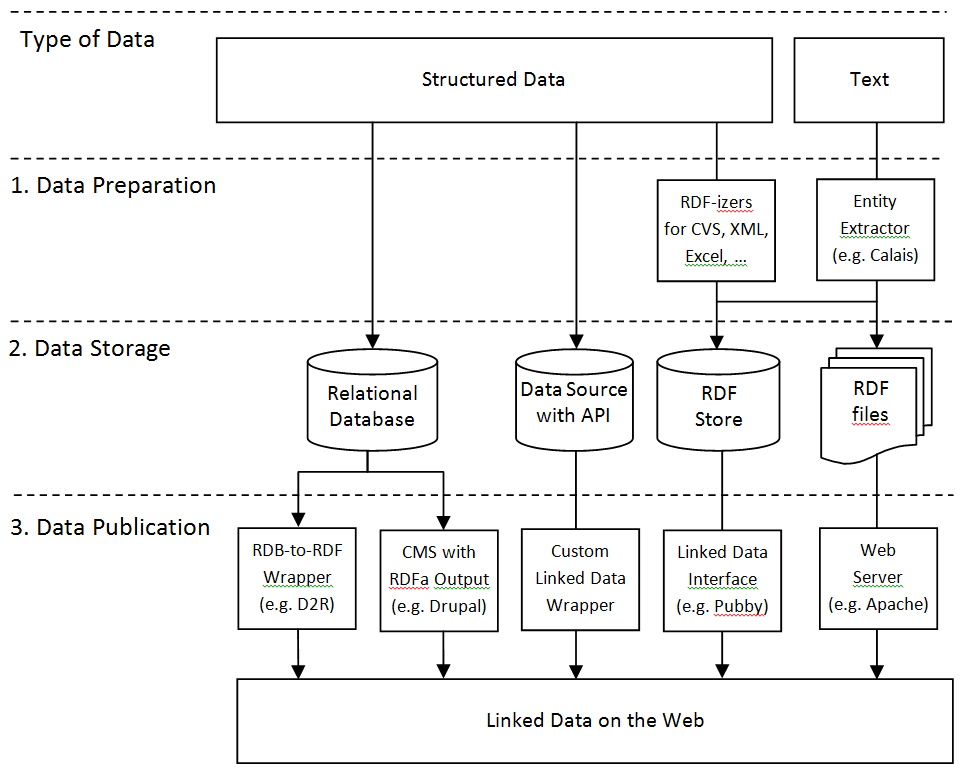
Publicar datos en LD
- Crear el dataset
- Ontología OWL: reusar lo más posible de otras ontologías para interoperabilidad
- Instancias RDF
- Añadir enlaces a otros datasets
- Manualmente o con herramientas como SILK
- A nivel de instancias (owl:sameAs, predicados, ...) y a nivel de vocabulario (owl:equivalentClass, ...)
Publicar datos en LD
- Almacenar el dataset en triple store
- Publicar el dataset mediante servidor web
- Registrar el dataset en Data Hub
- Generar archivo voiD (Vocabulary of Interlinked Datasets): http://www.w3.org/TR/void/
- Generar archivo sitemap.xml (con sitemap4RDF) y enviarlo a Semantic Web index (http://sindice.com/) y Google
Publicar datos en LD
Ejercicio práctico: recrear todo el proceso de publicar un dataset Linked Data
Crear el dataset y "publicarlo" en una infraestructura ya lista (Life Sciences Linked Data)
Life Sciences Linked Data
"Pack" ya listo y configurado para publicar Linked Data en localhost (Solo para GNU/Linux)
Life Sciences Linked Data
Fuseki: triple store
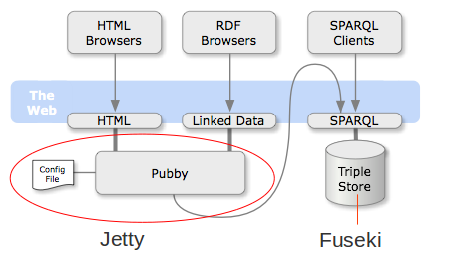
Jetty: servidor web
Pubby: negociacion contenido etc.
Life Sciences Linked Data
Probar con el dataset por defecto en biomaster.atica.um.es
Instrucciones: http://github.com/mikel-egana-aranguren/LSLD#running-with-the-default-dataset
Life Sciences Linked Data
Publicar el dataset de ejemplo con enlaces a otros datasets LOD biomaster.atica.um.es
Instrucciones: http://github.com/mikel-egana-aranguren/LSLD#running-with-a-different-dataset
Life Sciences Linked Data
- Cada pareja tiene dos puertos asignados
localhosthttp://biomaster.atica.um.es/- Invocar Fuseki en otro puerto (doc)
- ejecutar s-put en otro dominio/puerto
- Editar web.xml para que apunte a lsld-toy-config-file.ttl
- Editar lsld-toy-config-file.ttl en 3 sitios (dominio/puerto)
- Ejecutar jetty en un dominio differente
Life Sciences Linked Data
Crear vuestro propio dataset con Protégé 4 (http://protege.stanford.edu/) (Demo Protégé?)
Con enlaces a otros datasets
Publicar el dataset en localhost
Life Sciences Linked Data
Silk ...
Inferencia con P4: materializar triples ...
Sumario herramientas para LD
- Triple strores y APIs: Jena, Virtuoso, Sesame, OWL API, ...
- Editores ontologías: Protégé, TopBraid composer, ...
- Publicar LD: Silk, Pubby, ...
- Validadores: Vapour, RDF:Alerts, Sindice inspector, ...
- ...
Semantic Web Services
SADI
SADI: Semantic Automated Discovery and Integration
http://code.google.com/p/sadi/
SADI
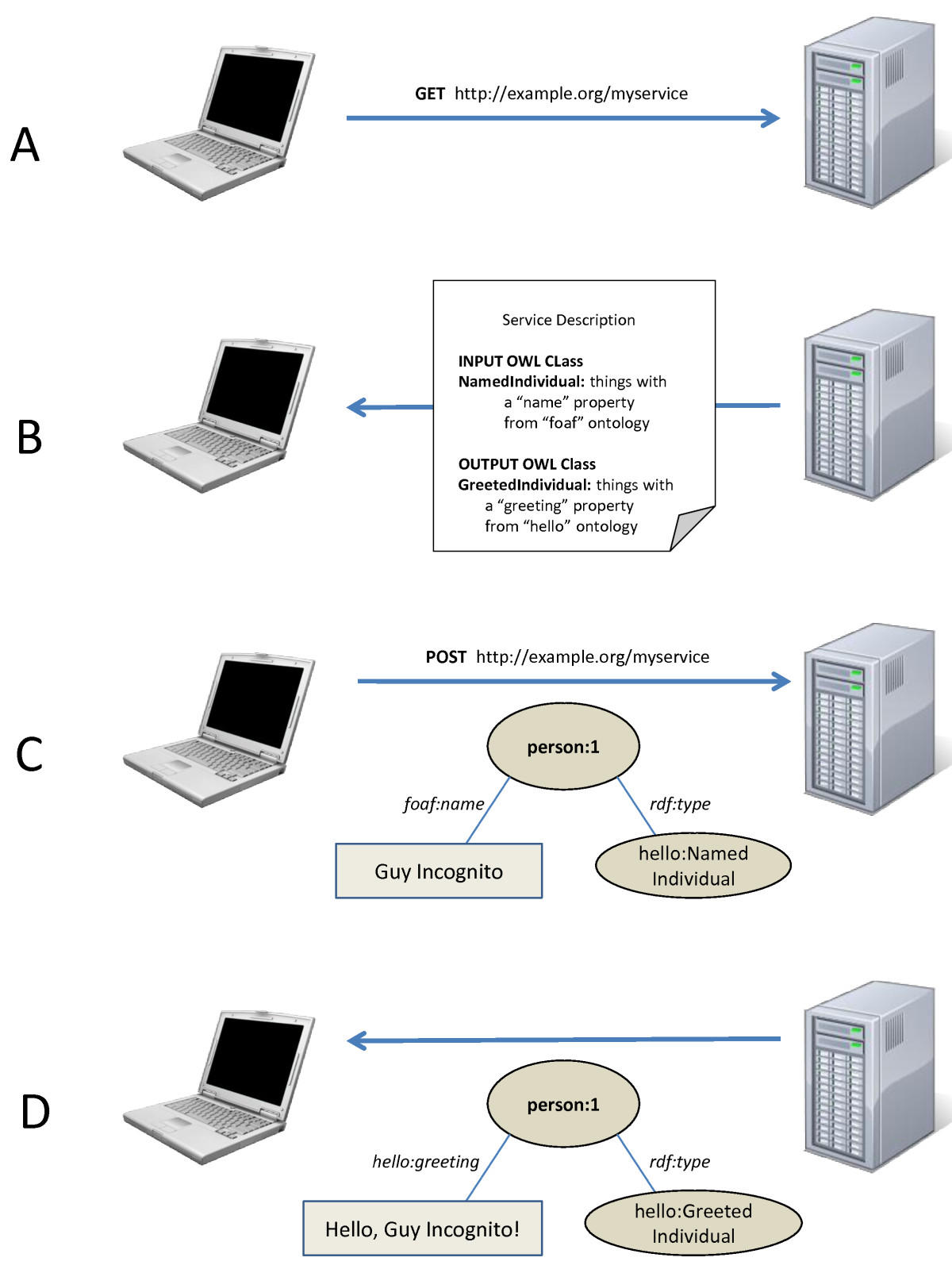
SADI ejercicio 1
Crear un servicio SADI en Python (en uno de los puertos asignados)
http://code.google.com/p/sadi/wiki/BuildingServicesInPython (Creating_the_Python_SADI_service)
Más información
Más información
Linked Data, the story so far (Christian Bizer, Tom Heath, Tim Berners-Lee)
Linked Data: Evolving the Web into a Global Data Space (Christian Bizer, Tom Heath)
Semantic Web Health Care and Life Sciences Interest Group (W3C HCLS IG): Health Care and Life Science (HCLS) Linked Data Guide
Más información
Programming the Semantic Web (O'Reilly)