Crítica a Linked Data en Open Data Euskadi
A través de un txio de @alorza he llegado al anuncio que hace Open Data Euskadi sobre la publicación de algunos datasets usando tecnología Linked Data (LD). Lo que sigue es mi análisis no exhaustivo y preliminar de los problemas que he visto, con la intención de ser constructivo y que el servicio mejore. El análisis es sobre esta noticia en concreto, desconozco si el Gobierno Vasco ha publicado mas datos con LD.
Primero un inciso para los que no saben lo que es Linked Data (También se puede ver un video divulgativo). La web actual es una colección de documentos (Páginas HTML) enlazados; un sistema indiscutiblemente útil para leer documentos, pero si hay que hacer consultas un poco complejas sobre la información que representan esos documentos, solo nos queda procesar los documentos y extraer de alguna manera la información que necesitamos. LD es una serie de principios y tecnologías que da respuesta a ese problema: con Linked Data, usando la infraestrutura web ya existente (HTTP + URL), podemos publicar datos directamente en la web en vez de hacerlo a través de documentos. LD tiene dos ventajas importantes: se pueden crear enlaces entre diferentes datos (igual que con las páginas HTML) y como se usa RDF, basado en la estructura del triple, el significado de la información es explícita (por ejemplo se pueden programar agentes automáticos que consuman los datos). Esto hace que los datos publicados con LD sean fácilmente reusables e integrables con otros datos, de modo que muchos gobiernos publican sus datos con este paradigma, como es el caso del Reino Unido.
Volviendo a la noticia original, lo primero que llama la atención es la distinción que se hace sobre usuarios: a los programadores les gustan las APIs, a los periodistas Excell, y a los que trabajan en innovación (?) LD. Realmente es una distinción arbitraria donde las haya, ya que hay programadores y periodistas que trabajan con LD, y ni siquiera sé a que se refiere el autor con “innovacion”. No hay que presuponer que un tipo de usuarios vayan a acceder de una manera concreta a la información: lo mejor es proveer esa información con los mecanismos más eficientes, y LD es uno de esos mecanismos (Aunque en este caso se ha usado de una manera que limita su propia eficiencia, como veremos a continuación).
Hay otra idea discutible en la introducción: la idea que las APIs son “más avanzadas”. No voy a entrar en el debate APIs vs. Linked Data (Creo que las dos tecnologías tienen sus meritos y de hecho son complementarias) pero no creo que usar APIs sea “más avanzado”: por ejemplo, algo que se reconoce en la misma noticia, con una API los métodos de acceso son locales a ese recurso y limitados por el proveedor: con LD se puede acceder a la información completa de ese recurso, y además con una esquema que se conoce a priori (solo cambia el contenido de recurso a recurso) lo cual la hace, en mi opinión, más avanzada que una API. Por decirlo de otra manera: OWL y RDF están “autodocumentados”, lo cual no quiere decir que sea más facil programar contra ellos, simplemente los problemas se desplazan a un nivel de abstracción (para mi gusto) más manejable.
Ahora ya entrando en los datasets que se mencionan en la noticia, no entiendo por que se usa como formato de serialización Turtle (TTL), que se suele usar para datasets pequeños y dirigidos a consumo humano. Para estos datasets seria mas adecuado RDF/XML.
Vamos a mirar un dataset concreto, por ejemplo el que describe los consulados (http://opendata.euskadi.net/w79-contdata/es/contenidos/ds_localizaciones/consulados/es_euskadi/index.shtml). El archivo RDF (en formato TTL) usa el vocabulario vCard para listar los consulados de Euskadi, lo cual está muy bien (no todo iba a ser malo :P) ya que una de la ideas principales de LD es aumentar la interoperabilidad mediante el uso de vocabularios compartidos.
Vamos a mirar el contenido de un consulado concreto, el consulado de Suiza (Lo he transformado a la sintaxis RDF/XML):
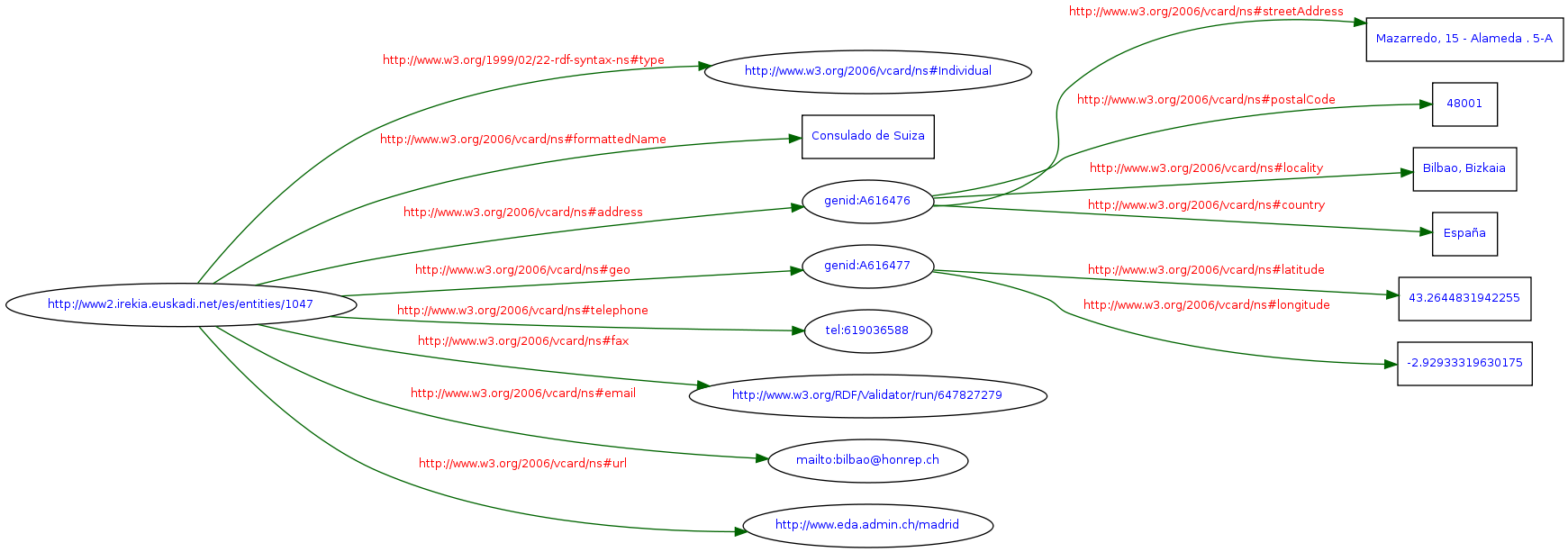
Lo primero es que hay nodos anónimos (Blank Nodes), lo cual es una mala práctica si el modelo RDF que hemos creado va a ser consumido como LD (ver “RDF Features Best Avoided in the Linked Data Context” http://linkeddatabook.com/editions/1.0/#htoc16), aunque puede que esta decisión venga impuesta por el uso de vCard.
Vemos que hay una URI que denota al consulado de Suiza: http://www2.irekia.euskadi.net/es/entities/1047. Una de las ideas principales de Linked Data (y la que mas quebraderos de cabeza da a programadores y usuarios, pero muy importante que se implemente correctamente) es que las URIs identifican a entidades, no a sus representaciones. Cuando un agente (por ejemplo alguien navegando con su navegador web favorito) quiera acceder a esa entidad, recibira una representacion u otra (RDF si es un agente automatico, HTML si el agente es una persona, etc.) mediante negociación de contenido. Veamos que pasa si intentamos hacer un poco de negociación de contenido contra http://www2.irekia.euskadi.net/es/entities/1047 (con la ayuda de http://richard.cyganiak.de/blog/2007/02/debugging-semantic-web-sites-with-curl/):
Simulamos ser un navegador web normal, es decir un ser humano pide la entidad http://www2.irekia.euskadi.net/es/entities/1047:
curl http://www2.irekia.euskadi.net/es/entities/1047
Esto nos lleva efectivamente a la página HTML (Uno de los enlaces dentro de la página apunta al archivo TTL). Para un humano es suficiente.
Pero que pasa si un agente automático (por ejemplo un programa que consume RDF para generar estadísticas sobre consulados) quiere acceder a la entidad consulado de suiza?
curl --header "Accept: application/rdf+xml" http://www2.irekia.euskadi.net/es/entities/1047
Que recibe HTML (lo mismo que el humano), no el RDF que está pidiendo (pasa lo mismo si usamos la cabecera “Accept: text/turtle”). De modo que el programa lo tendrá dificil para generar la estadística (aunque no imposible). Se podria argumentar que puesto que el agente necesita RDF, vaya directamente a http://www2.irekia.euskadi.net/es/entities/1047-consulado-suiza.ttl, pero ese diseño va completamente en contra de LD y del sentido común, puesto que:
- La URI dentro del documento TTL que denota el consulado de Suiza es http://www2.irekia.euskadi.net/es/entities/1047, no http://www2.irekia.euskadi.net/es/entities/1047-consulado-suiza.ttl
- El agente tendría que consumir primero la página HTML y descubrir un enlace a un archivo TTL (Si esa era la intención, deberían haber usado RDFa).
Otro problema con este dataset (e intuyo que con muchos de los que habla esta noticia, pero no lo he comprobado) es que no tiene ningún enlace a un dataset externo, con lo cual es tan inútil como usar HTML para escribir un documento, imprimirlo y mandarlo por fax (para eso usariamos un procesador de textos): la gracia de HTML son los enlaces, y sin ellos es una tecnología que no tiene ningun sentido. De igual manera, la gracia de RDF son los enlaces, que, acoplados al hecho de que se usa los triples para representar informacion, hará que quizás algún día toda la web se comporte como una base de datos universal. Asi que para usar RDF y no enlazar a otros datasets, mejor no usarlo: el formato vCard, por si mismo, es perfectamente válido.
De modo que este dataset, al no tener enlaces hacia otros datasets ni desde otros datasets hacia él, está completamente fuera de la red mundial de datos abiertos (http://lod-cloud.net/) y por consiguiente:
- No pueder ser descubierto.
- No se puede combinar informacion con facilidad. Por ejemplo, si el gobierno de suiza tiene una URI para cada consulado, se podrían integrar los datos siguiendo la filosofía LD (y asumiendo que efectivamente la negociación se implementase correctamente como he comentado más arriba).
Por último, normalmente para publicar un dataset en LD se usa una triple store para cargar todos los triples, y algo como Pubby para hacer la “magia LD” contra el SPARQL endpoint del triple store (Ver http://biordf.org/UM_LSLD/Clases/UM_Bioinformatics_LD.html#/8/9). Sin embargo, en este caso parece no haber SPARQL endpoint, de modo que tampoco se pueden hacer consultas complejas.
En resumidas cuentas, parece que se ha usado el nombre LD en vano, ya que usar archivos RDF no garantiza que estemos publicando en LD. Quizás hubiese sido mejor estrategia centrarse en unos pocos datos y publicarlos de verdad siguiendo los principios LD mas que publicar todos estos datasets con RDF, sin un beneficio claro, para “colgarse la medalla” (Dicho con todo el respeto y desde un análisis preliminar hecho en timpo libre ;-).